Passo a Passo para uma Análise Exploratória de Dados Eficiente
Exemplo de análise exploratória utilizando a base de dados Data Science Salaries 2023 do Kaggle

Olá, amantes de dados!
Você já se deparou com um conjunto de dados e se perguntou por onde começar a extrair informações valiosas? A Análise Exploratória de Dados (EDA) é a resposta para essa pergunta! Neste post, apresentaremos um guia passo a passo que o ajudará a realizar uma EDA eficiente e obter insights significativos dos seus dados.
Para isso, vamos utilizar a base de dados Data Science Salaries 2023 do Kaggle. Essa base de dados contém informações sobre os salários de profissionais de ciência de dados em diferentes regiões e setores.
Sobre os dados
O conjunto de dados refere-se aos salários de diferentes profissionais de ciência de dados, mensurados nas seguintes características:
- work_year: O ano em que o salário foi pago.
- experience_level: O nível de experiência no trabalho durante o ano.
- employment_type: O tipo de emprego para a função.
- job_title: O cargo exercido durante o ano.
- salary: O valor total do salário bruto pago.
- salary_currency: A moeda do salário pago, representada por um código ISO 4217.
- salary_in_usd: O salário em USD (dólares americanos).
- employee_residence: O país de residência principal do funcionário durante o ano de trabalho, representado por um código ISO 3166.
- remote_ratio: A quantidade geral de trabalho realizado remotamente.
- company_location: O país da sede da empresa ou filial contratante.
- company_size: O número médio de pessoas que trabalharam para a empresa durante o ano.
Pacotes utilizados
load <- function(pkg){
new.pkg <- pkg[!(pkg %in% installed.packages()[, "Package"])]
if (length(new.pkg))
install.packages(new.pkg, dependencies = TRUE)
sapply(pkg, require, character.only = TRUE)
}
packages <- c("tidyverse",'tidymodels', 'janitor', 'ggpubr', 'funModeling', 'ggalluvial', 'vip', 'skimr',
'VIM', 'patchwork', 'monochromeR', 'googleVis', 'treemapify')
load(packages)
## tidyverse tidymodels janitor ggpubr funModeling ggalluvial
## TRUE TRUE TRUE TRUE TRUE TRUE
## vip skimr VIM patchwork monochromeR googleVis
## TRUE TRUE TRUE TRUE TRUE TRUE
## treemapify
## TRUE
Leitura dos dados
dados = read.csv('ds_salaries.csv', stringsAsFactors = TRUE)
dados %>%
glimpse()
## Rows: 3,755
## Columns: 11
## $ work_year <int> 2023, 2023, 2023, 2023, 2023, 2023, 2023, 2023, 202…
## $ experience_level <fct> SE, MI, MI, SE, SE, SE, SE, SE, SE, SE, SE, SE, SE,…
## $ employment_type <fct> FT, CT, CT, FT, FT, FT, FT, FT, FT, FT, FT, FT, FT,…
## $ job_title <fct> Principal Data Scientist, ML Engineer, ML Engineer,…
## $ salary <int> 80000, 30000, 25500, 175000, 120000, 222200, 136000…
## $ salary_currency <fct> EUR, USD, USD, USD, USD, USD, USD, USD, USD, USD, U…
## $ salary_in_usd <int> 85847, 30000, 25500, 175000, 120000, 222200, 136000…
## $ employee_residence <fct> ES, US, US, CA, CA, US, US, CA, CA, US, US, US, US,…
## $ remote_ratio <int> 100, 100, 100, 100, 100, 0, 0, 0, 0, 0, 0, 100, 100…
## $ company_location <fct> ES, US, US, CA, CA, US, US, CA, CA, US, US, US, US,…
## $ company_size <fct> L, S, S, M, M, L, L, M, M, M, M, M, M, L, L, M, M, …
O primeiro passo é entender qual é o objetivo da nossa análise. Neste caso, nosso objetivo pode ser identificar os principais fatores que influenciam os salários de profissionais de ciência de dados e explorar as tendências salariais em diferentes regiões e setores. Tentaremos responder às seguintes perguntas:
- Qual a dimensão da base de dados?
- Quando foram pagos os salários?
- Qual o nível de experiência da maioria dos profissionais?
- Quais os tipos de contrato de trabalho?
- Como está a distribuição dos salários no mercado?
- Quais as modalidades de trabalho?
- Qual o tamanho das empresas?
- onde as empresas estão alocadas?
- Onde se pagam os maiores salários médios?
- Onde os empregados vivem?
- Quais são os principais cargos de trabalho?
- Qual a faixa salarial de acordo com o cargo?
- Existe alguma relação entre o tamanho da empresa e a faixa salarial?
- Existe alguma relação entre o nível de experiência e a faixa salarial?
- Qual o valor que separa os 10% maiores salarios recebidos e qual a relação com o nível de experiência do profissional?
- Qual a relação entre os maiores salários com o tipo de contrato do profissional?
- Qual a relação entre os maiores salários com modalidade de trabalho do profissional?
Qual a dimensão da base de dados?
dados %>%
dim()
## [1] 3755 11
Note que a base de dados possui 3755 registros mensurados nas 11 variáveis.
Quando foram pagos os salários?
dados %>%
ggplot((aes(x=work_year))) +
geom_bar(stat = 'count', fill= 'steelblue')+
xlab("Ano") +
ylab("Frequência Absoluta") +
stat_count(geom = "text", aes(label = after_stat(count)), vjust = -0.5) +
theme_pubclean()
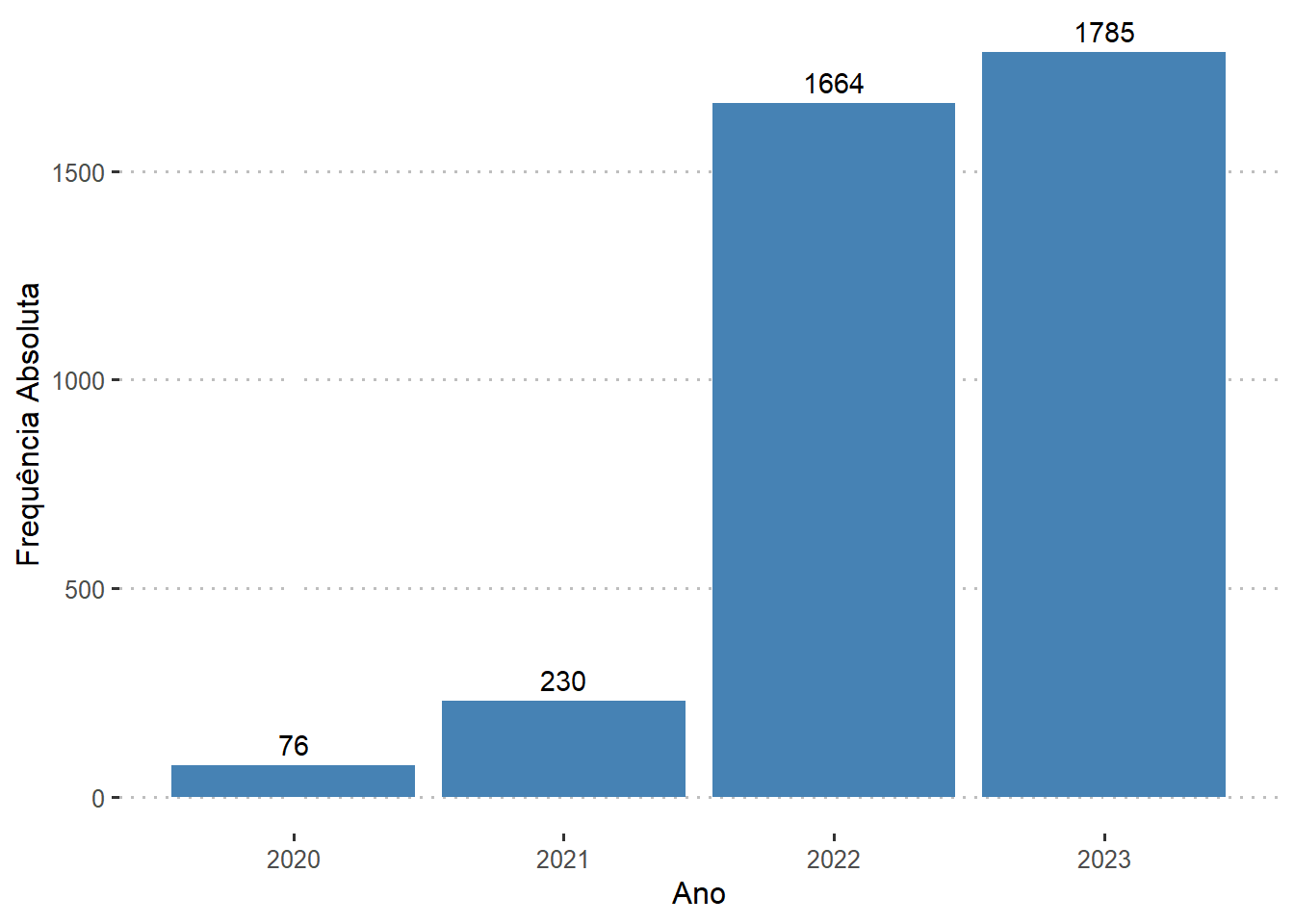
Perceba que a grande maioria dos salários foram pagos nos anos de 2022 e 2023.
Qual o nível de experiência da maioria dos profissionais?
dados %>%
ggplot((aes(x=experience_level))) +
geom_bar(stat = 'count', fill= 'steelblue')+
xlab("Nível de experiência") +
ylab("Frequência Absoluta") +
stat_count(geom = "text", aes(label = after_stat(count)), vjust = -0.5) +
theme_pubclean()
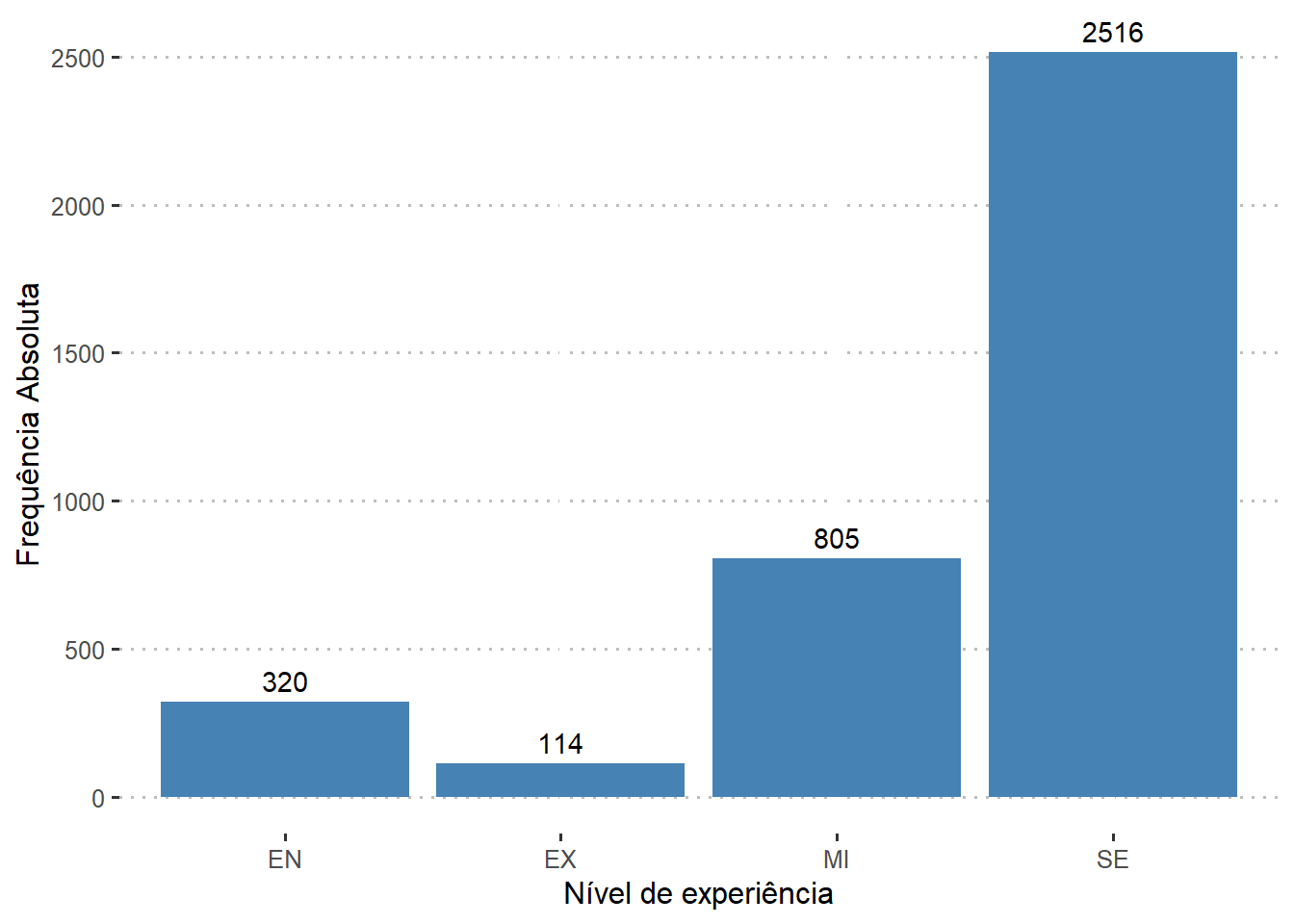
O conjunto de dados contém 4 níveis de experiência, dos quais a categoria de nível sênior (SE) tem a representação mais alta, seguida pela categoria pleno (MI), a categoria júnior (EN) é a próxima na linha e a categoria de nível executivo (EX) tem a representação mais baixa.
Quais os tipos de contrato de trabalho?
dados %>%
ggplot((aes(x=employment_type))) +
geom_bar(stat = 'count', fill= 'steelblue')+
xlab("Modalidade") +
ylab("Frequência Absoluta") +
stat_count(geom = "text", aes(label = after_stat(count)), vjust = -0.5) +
theme_pubclean()
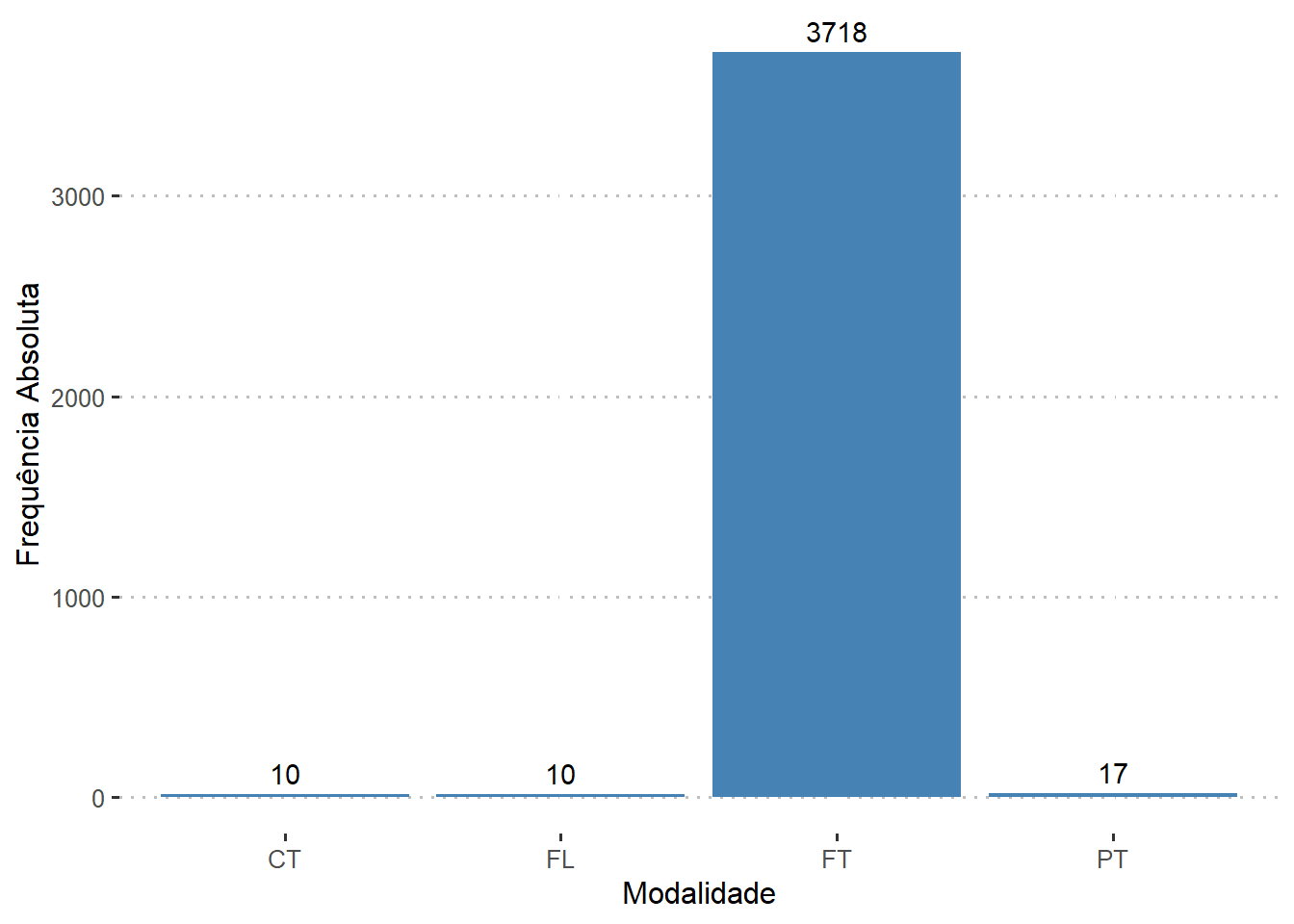
O conjunto de dados contém 4 tipos contrato de trabalho: Contrato (CT), Freelance (FL), Full-Time (FT) e Part-Time (PT). É evidente a partir dos gráficos que a maioria das pessoas trabalha em regime de tempo integral.
Como está a distribuição dos salários no mercado?
dados %>%
select(salary_in_usd) %>%
summary()
## salary_in_usd
## Min. : 5132
## 1st Qu.: 95000
## Median :135000
## Mean :137570
## 3rd Qu.:175000
## Max. :450000
quantile(dados$salary_in_usd)
## 0% 25% 50% 75% 100%
## 5132 95000 135000 175000 450000
dados %>%
mutate(
salary_range = cut_number(salary_in_usd, 4, labels = c("low", "medium", "high", "very high"))
) %>%
group_by(salary_range) %>%
summarise(
`Qtd de observações` = n(),
`Vlr Min` = min(salary_in_usd),
`Vlr Max` = max(salary_in_usd)
)
## # A tibble: 4 × 4
## salary_range `Qtd de observações` `Vlr Min` `Vlr Max`
## <fct> <int> <int> <int>
## 1 low 956 5132 95000
## 2 medium 967 95386 135000
## 3 high 900 135446 175000
## 4 very high 932 175100 450000
p = dados %>%
ggplot((aes(x=salary_in_usd))) +
geom_histogram(color = '#0F4B63', fill ='steelblue', bins=30) +
labs(title = "Histograma de Salário ($)",x = "Salário",y = "Frequência Absoluta") +
theme_pubclean()
p + geom_vline(xintercept = quantile(dados$salary_in_usd), colour="red", linewidth = 0.6, linetype = 2)

A faixa salarial está entre 5132,00 dólares e 450000,00 dólares. O salário médio dos profissionais de Data Science é de aproximadamente 137570,00 dólares. Considerando os quartis, podemos criar uma variável chamada salary_range com as faixas salariais, sendo que aproximadamente 25% dos empregados (956 observações) recebem entre 5132,00 e 9500,00 dólares (low), aproximadamente 25% (967 observações) recebem entre 95386,00 e 135000,00 dólares (medium). Aproximadamente 25% (900 observações) recebem entre 135446,00 e 175000,00 dólares (high) e finalmente, aproximadamente 25% (932 observações) recebem entre 175100,00 e 450000,00 dólares (very high).
Quais são os principais cargos de trabalho?
dados %>%
select(job_title) %>%
group_by(job_title) %>%
summarise(N = n()) %>%
mutate(Porcentagem = round(N / sum(N), 3)) %>%
arrange(desc(Porcentagem))
## # A tibble: 93 × 3
## job_title N Porcentagem
## <fct> <int> <dbl>
## 1 Data Engineer 1040 0.277
## 2 Data Scientist 840 0.224
## 3 Data Analyst 612 0.163
## 4 Machine Learning Engineer 289 0.077
## 5 Analytics Engineer 103 0.027
## 6 Data Architect 101 0.027
## 7 Research Scientist 82 0.022
## 8 Applied Scientist 58 0.015
## 9 Data Science Manager 58 0.015
## 10 Research Engineer 37 0.01
## # ℹ 83 more rows
dados %>%
select(job_title) %>%
group_by(job_title) %>%
summarise(N = n()) %>%
mutate(Porcentagem = round(N / sum(N), 3)) %>%
ggplot(aes(area = N, fill = Porcentagem, label = paste(job_title, paste0(Porcentagem*100, '%'), sep = "\n"))) +
geom_treemap()+
geom_treemap_text(colour = "white",
place = "centre",
size = 15) +
theme(legend.position = "none")
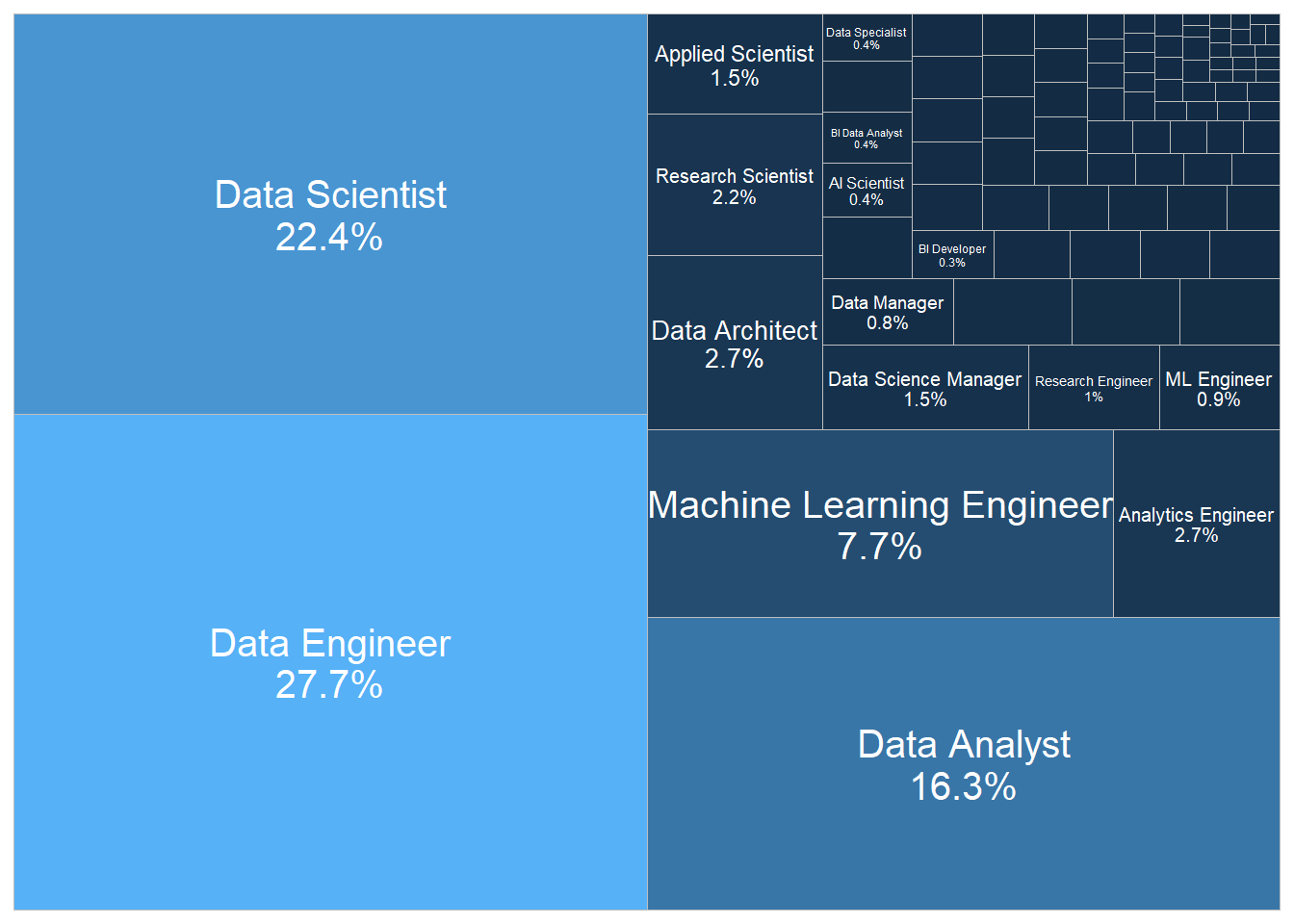
O conjunto de dados mostra que 27,7% (1040 observações) do total de empregados são lotados como Data Engineer, 22,4% (840 observações) são lotados como Data Scientist, 16,3% (612 observações) são lotados como Data Analyst e 7,7% (289 observações) são lotados como Machine Learning Engineer. Outros cargos aparecem na base de dados, mas com porcentagem menores.
Qual a faixa salarial de acordo com o cargo?
Existem muitos cargos citados na base de dados. Vamos visualizar apenas as mais citadas e sua relação com as faixas salariais.
dados = dados %>%
mutate(top10Salary = as.factor(ifelse(salary_in_usd > quantile(dados$salary_in_usd, probs = 0.9), 'yes', 'no')),
salary_range = cut_number(salary_in_usd, 4,
labels = c("low", "medium", "high", "very high")))
job_freq = dados %>%
group_by(job_title) %>%
dplyr::summarise(N=n()) %>%
arrange(desc(N)) %>%
filter(N > 20)
dadosT = dados %>%
inner_join(job_freq) %>%
group_by(job_title, salary_range) %>%
dplyr::summarise(N = n()) %>%
arrange(salary_range, N)
## Definir um número de 'barras vazias' para adicionar no final de cada grupo
empty_bar <- 2
to_add <- data.frame( matrix(NA, empty_bar*nlevels(dadosT$salary_range), ncol(dadosT)) )
colnames(to_add) <- colnames(dadosT)
to_add$salary_range <- rep(levels(dadosT$salary_range), each=empty_bar)
dadosT <- rbind(dadosT, to_add)
dadosT <- dadosT %>% arrange(salary_range)
dadosT$id <- seq(1, nrow(dadosT))
## Obter o nome e a posição y de cada rótulo
label_dadosT <- dadosT
number_of_bar <- nrow(label_dadosT)
angle <- 90 - 360 * (label_dadosT$id-0.5) /number_of_bar
label_dadosT$hjust <- ifelse( angle < -90, 1, 0)
label_dadosT$angle <- ifelse(angle < -90, angle+180, angle)
## Gráfico
p <- ggplot(dadosT, aes(x=as.factor(id), y=N, fill=salary_range)) +
geom_bar(stat="identity", alpha=0.5) +
ylim(-100,120) +
theme_minimal() +
theme(
axis.text = element_blank(),
axis.title = element_blank(),
panel.grid = element_blank(),
plot.margin = unit(rep(-1,4), "cm")
) +
coord_polar() +
geom_text(data=label_dadosT, aes(x=id, y=N+10, label=job_title, hjust=hjust), color="black", fontface="bold",alpha=0.6, size=2.5, angle= label_dadosT$angle, inherit.aes = FALSE )
p
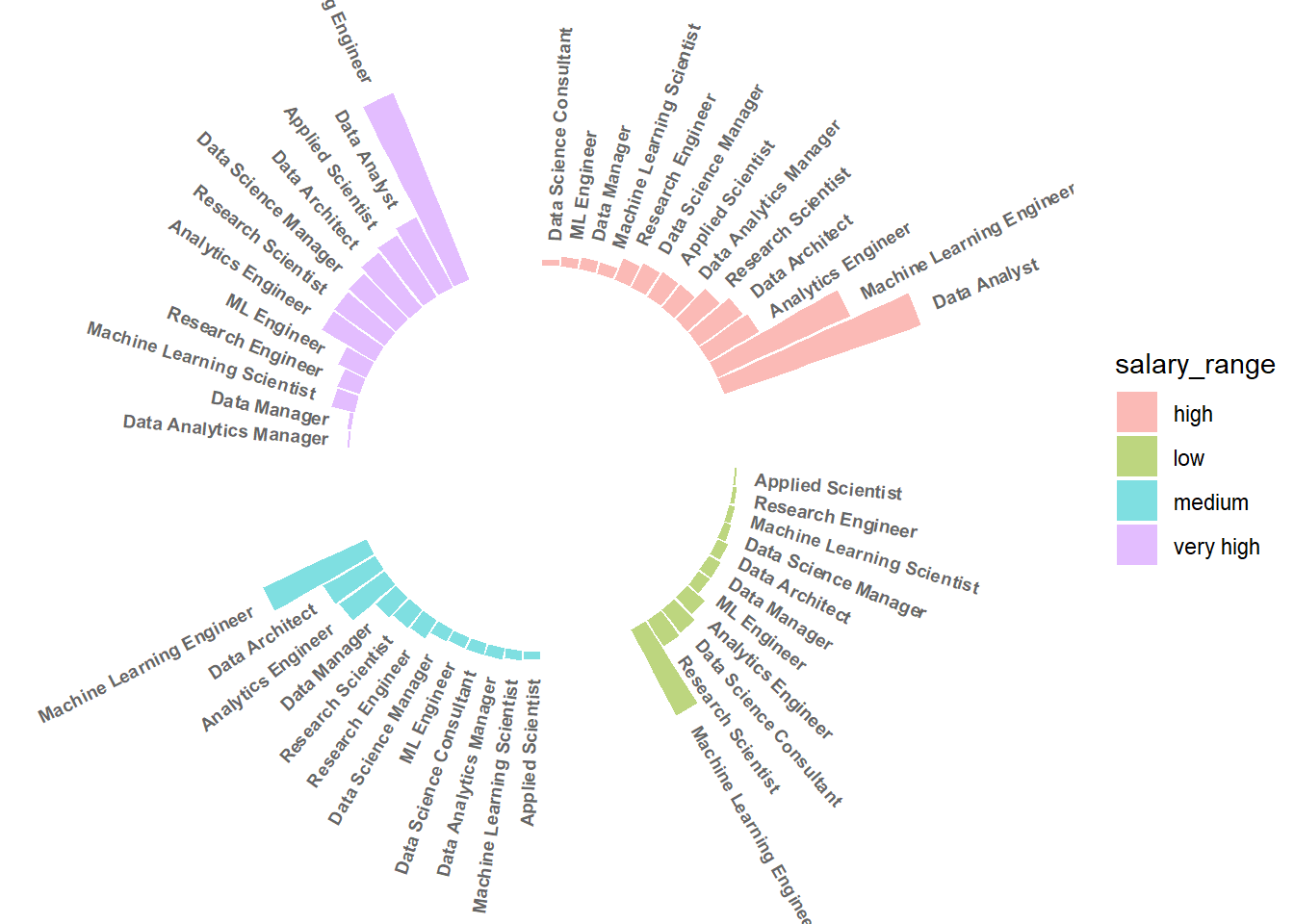
Note que, em todas as faixas salariais, o cargo mais frequente é o de Machine Learning Engineer, exceto para quem ganha entre 135446,00 e 175000,00 dólares (high) cujo cargo mais frequente é Data Analyst.
Qual o tamanho das empresas?
dados %>%
group_by(company_size) %>%
summarise(N = n()) %>%
mutate(Porcentagem = round(N / sum(N), 3)) %>%
arrange(desc(Porcentagem))
## # A tibble: 3 × 3
## company_size N Porcentagem
## <fct> <int> <dbl>
## 1 M 3153 0.84
## 2 L 454 0.121
## 3 S 148 0.039
dados %>%
ggplot((aes(x=company_size))) +
geom_bar(stat = 'count', fill= 'steelblue')+
xlab("Tamanho") +
ylab("Frequência Absoluta") +
stat_count(geom = "text", aes(label = after_stat(count)), vjust = -0.5) +
theme_pubclean()
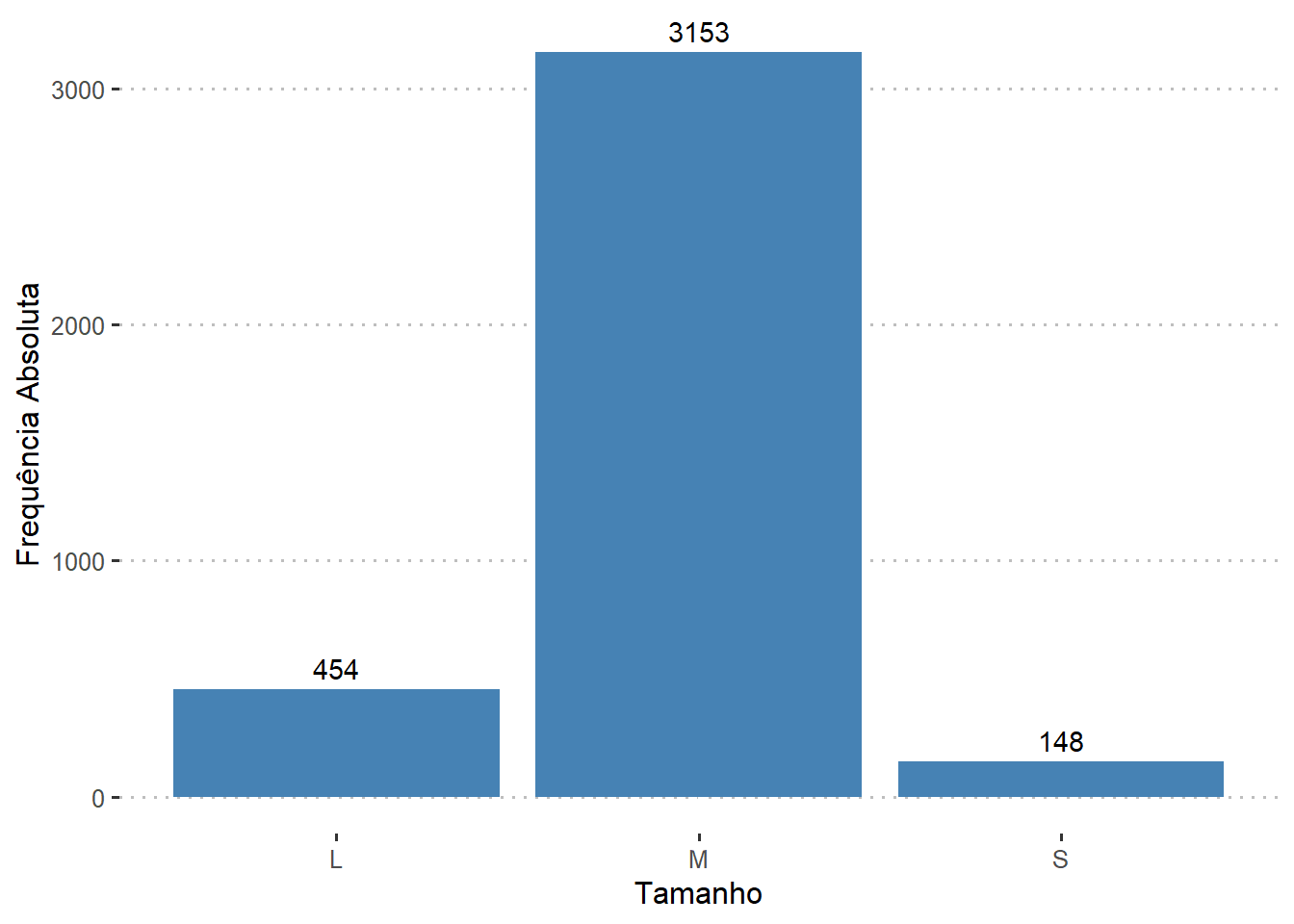
O conjunto de dados mostra que 3,9% (148 observações) das empresas são de pequeno porte (S), 84,0% (3153 observações) são empresas de médio porte (M) e 12,1% (454 observações) são empresas de grande porte (L).
Existe alguma relação entre o tamanho da empresa e a faixa salarial?
dados %>%
group_by(company_size, salary_range) %>%
dplyr::summarise(N=n())%>%
mutate(Porcentagem = round(N / sum(N), 3))
## # A tibble: 12 × 4
## # Groups: company_size [3]
## company_size salary_range N Porcentagem
## <fct> <fct> <int> <dbl>
## 1 L low 193 0.425
## 2 L medium 98 0.216
## 3 L high 68 0.15
## 4 L very high 95 0.209
## 5 M low 658 0.209
## 6 M medium 844 0.268
## 7 M high 826 0.262
## 8 M very high 825 0.262
## 9 S low 105 0.709
## 10 S medium 25 0.169
## 11 S high 6 0.041
## 12 S very high 12 0.081
dados %>%
group_by(company_size, salary_range) %>%
dplyr::summarise(qtd = n()) %>%
ggplot(aes(axis1=company_size, axis2=salary_range, y=qtd, fill= company_size))+
geom_alluvium()+
geom_stratum()+
geom_text(stat = "stratum", aes(label = after_stat(stratum)))+
scale_x_discrete(limits = c("company_size", "salary_range"))+
theme_pubclean()
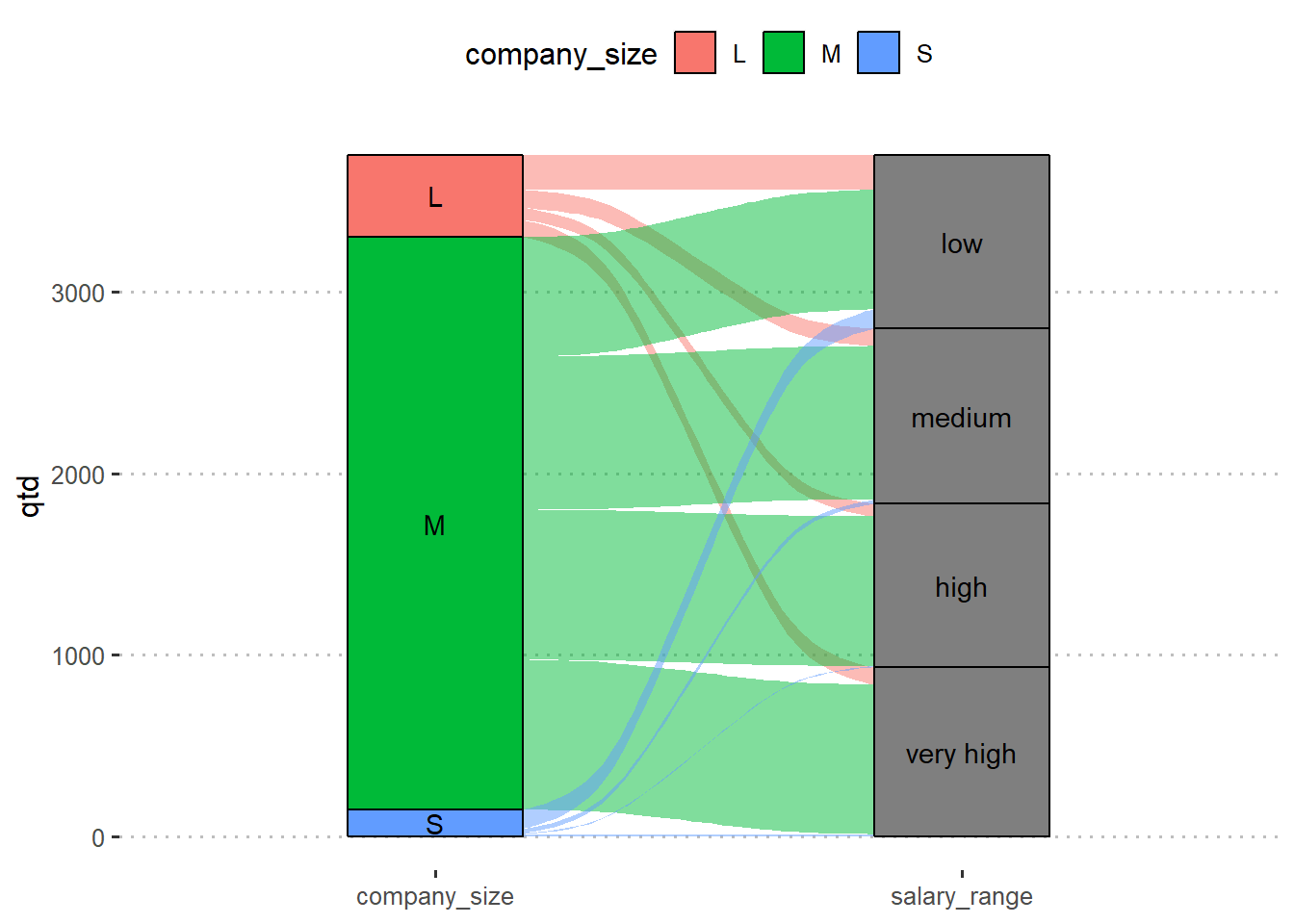
Podemos observar que, para as empresas de grande porte (L), 42,5% (193 observações) dos salários pagos são baixos, 21,6% (98 observações) dos salários pagos são medianos, 15% (68 obsevações) são altos e 20,9% (95 observações) são muito altos. Já para as empresas de pequeno porte, a grande maioria (70,9 %) pagam salários considerados baixos. As empresas de porte médio pagam os salários de forma bem distribuída entre as quatro faixas salariais.
Existe alguma relação entre o nível de experiência e a faixa salarial?
dados %>%
group_by(experience_level, salary_range) %>%
summarise(N = n()) %>%
mutate(Porcentagem = round(N / sum(N), 3))
## # A tibble: 16 × 4
## # Groups: experience_level [4]
## experience_level salary_range N Porcentagem
## <fct> <fct> <int> <dbl>
## 1 EN low 217 0.678
## 2 EN medium 62 0.194
## 3 EN high 26 0.081
## 4 EN very high 15 0.047
## 5 EX low 6 0.053
## 6 EX medium 18 0.158
## 7 EX high 24 0.211
## 8 EX very high 66 0.579
## 9 MI low 379 0.471
## 10 MI medium 229 0.284
## 11 MI high 133 0.165
## 12 MI very high 64 0.08
## 13 SE low 354 0.141
## 14 SE medium 658 0.262
## 15 SE high 717 0.285
## 16 SE very high 787 0.313
dados %>%
group_by(experience_level, salary_range) %>%
dplyr::summarise(qtd = n()) %>%
ggplot(aes(axis1=experience_level, axis2=salary_range, y=qtd, fill= experience_level))+
geom_alluvium()+
geom_stratum()+
geom_text(stat = "stratum", aes(label = after_stat(stratum)))+
scale_x_discrete(limits = c("experience_level", "salary_range"))+
theme_pubclean()
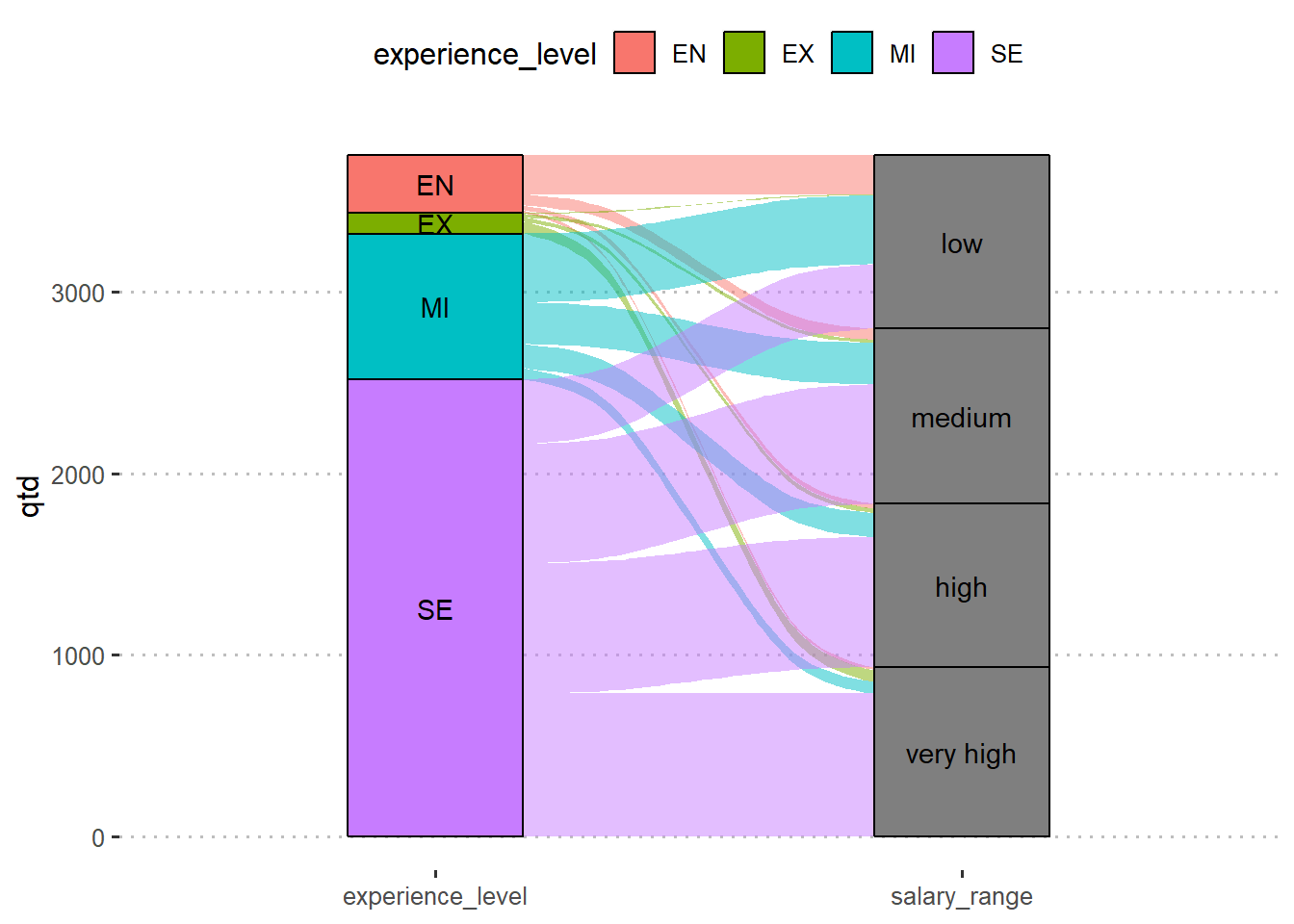
Podemos observar que a maioria dos empregados da categoria júnior (EN) (67,8% ou 217 observações) recebem salários considerados baixos (low). O mesmo acontece com os empregados da categoria pleno (MI) (47,1% ou 379 observações). Para os níveis sênior (SE) e executivo (EX), o padrão salarial se inverte. A maioria (31,3% e 57,9%, respectivamente) recebem salários considerados muito altos.
Quais as modalidades de trabalho?
dados %>%
ggplot((aes(x=factor(remote_ratio, labels = c('Presencial', 'Híbrido', 'Remoto'))))) +
geom_bar(stat = 'count', fill= 'steelblue')+
xlab("Modalidade") +
ylab("Frequência Absoluta") +
stat_count(geom = "text", aes(label = after_stat(count)), vjust = -0.5) +
theme_pubclean()
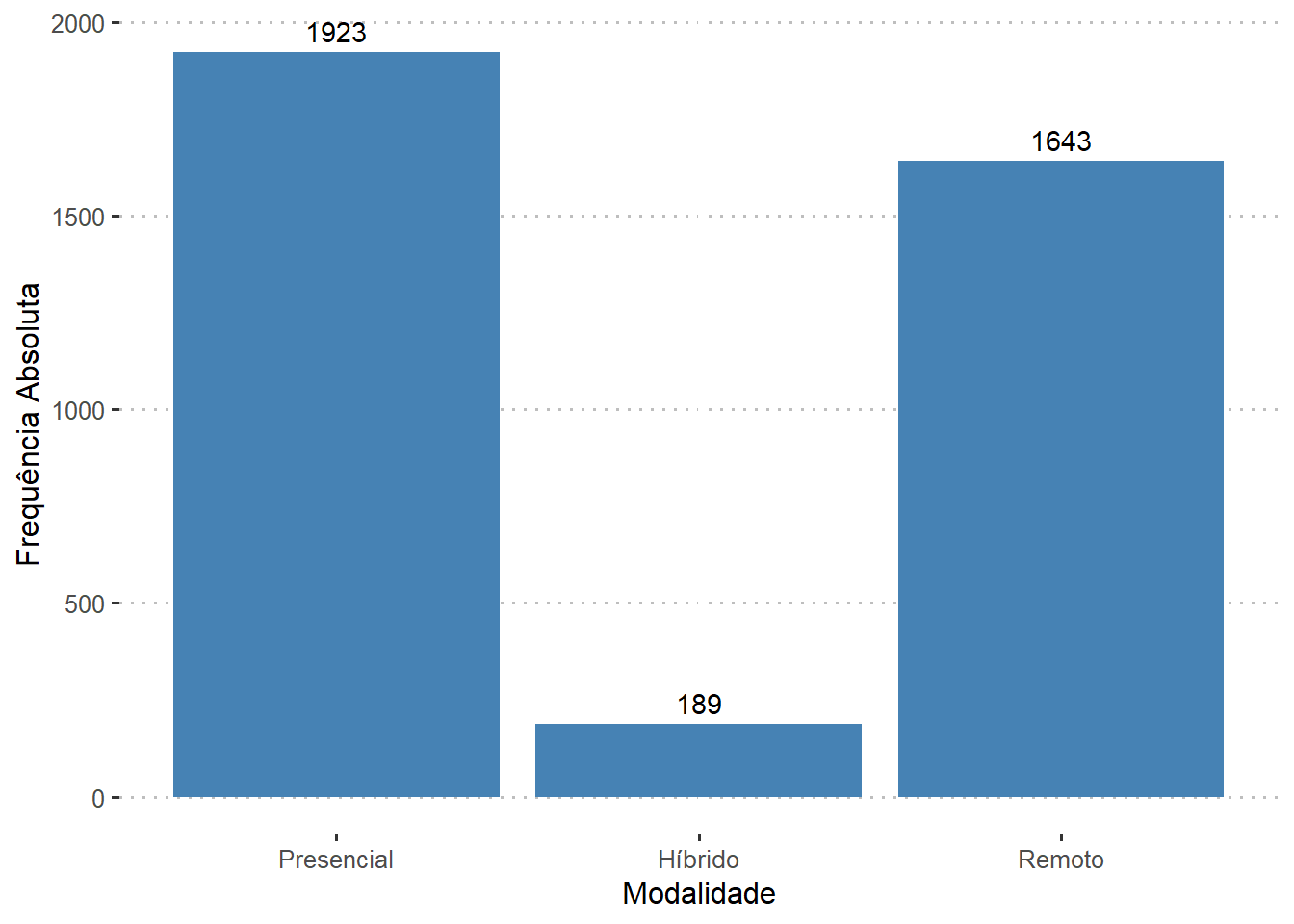
dados %>%
mutate(
remote_ratio = factor(remote_ratio, labels = c('Presencial', 'Híbrido', 'Remoto'))
) %>%
group_by(remote_ratio) %>%
summarise(`Qtd de observações` = n()) %>%
mutate(Porcentagem = round(`Qtd de observações` / sum(`Qtd de observações`), 3)) %>%
arrange(desc(Porcentagem))
## # A tibble: 3 × 3
## remote_ratio `Qtd de observações` Porcentagem
## <fct> <int> <dbl>
## 1 Presencial 1923 0.512
## 2 Remoto 1643 0.438
## 3 Híbrido 189 0.05
O conjunto de dados mostra que cerca de 51,2% (1.923 observações) estão trabalhando presencialmente, 43,8% (1.643 observações) estão trabalhando no modo híbrido e 5% (189 observações) estão trabalhando remotamente.
Onde os empregados vivem?
dados_g = dados %>%
group_by(employee_residence) %>%
summarise(N = n()) %>%
mutate(num_employee.tooltip = paste("Total de empregados:", N),
Tooltip.header = "") %>%
ungroup()
dados_g %>%
select(employee_residence, N) %>%
mutate(Porcentagem = round(N / sum(N), 3)) %>%
arrange(desc(Porcentagem))
## # A tibble: 78 × 3
## employee_residence N Porcentagem
## <fct> <int> <dbl>
## 1 US 3004 0.8
## 2 GB 167 0.044
## 3 CA 85 0.023
## 4 ES 80 0.021
## 5 IN 71 0.019
## 6 DE 48 0.013
## 7 FR 38 0.01
## 8 BR 18 0.005
## 9 PT 18 0.005
## 10 GR 16 0.004
## # ℹ 68 more rows
op = options(gvis.plot.tag = 'chart')
G = gvisGeoChart(dados_g, "employee_residence", "N",
options=list(projection="kavrayskiy-vii",
width=800, height=400))
plot(G)
Podemos observar que a grande maioria (80,0%) dos empregados moram nos Estados Unidos. Talvez seria interessante avaliar o gráfico acima fora dos Estados Unidos.
dados_sUS = dados %>%
filter(employee_residence != 'US') %>%
group_by(employee_residence) %>%
summarise(N = n()) %>%
mutate(num_employee.tooltip = paste("Total de empregados:", N),
Tooltip.header = "") %>%
ungroup()
dados_sUS %>%
select(employee_residence, N) %>%
mutate(Porcentagem = round(N / sum(N), 3)) %>%
arrange(desc(Porcentagem))
## # A tibble: 77 × 3
## employee_residence N Porcentagem
## <fct> <int> <dbl>
## 1 GB 167 0.222
## 2 CA 85 0.113
## 3 ES 80 0.107
## 4 IN 71 0.095
## 5 DE 48 0.064
## 6 FR 38 0.051
## 7 BR 18 0.024
## 8 PT 18 0.024
## 9 GR 16 0.021
## 10 NL 15 0.02
## # ℹ 67 more rows
op = options(gvis.plot.tag = 'chart')
G = gvisGeoChart(dados_sUS, "employee_residence", "N",
options=list(projection="kavrayskiy-vii",
width=800, height=400))
plot(G)
Note que, fora dos Estados Unidos, a maioria dos empregados vivem na Inglaterra (22,2%), Canadá (11,3%), Espanha (10,7%), Índia (9,5%), Alemanha (6,4%) e França (5,1%).
Onde as empresas estão alocadas?
dados_c = dados %>%
group_by(company_location) %>%
summarise(N = n()) %>%
mutate(num_company.tooltip = paste("Total de empresas:", N),
Tooltip.header = "") %>%
ungroup()
dados_c %>%
select(company_location, N) %>%
mutate(Porcentagem = round(N / sum(N), 3)) %>%
arrange(desc(Porcentagem))
## # A tibble: 72 × 3
## company_location N Porcentagem
## <fct> <int> <dbl>
## 1 US 3040 0.81
## 2 GB 172 0.046
## 3 CA 87 0.023
## 4 ES 77 0.021
## 5 DE 56 0.015
## 6 IN 58 0.015
## 7 FR 34 0.009
## 8 AU 14 0.004
## 9 BR 15 0.004
## 10 GR 14 0.004
## # ℹ 62 more rows
op = options(gvis.plot.tag = 'chart')
E = gvisGeoChart(dados_c, "company_location", "N",
options=list(projection="kavrayskiy-vii",
width=800, height=400))
plot(E)
Podemos observar que a grande maioria (81,0%) das empresas estão situadas nos Estados Unidos. Talvez seria interessante avaliar o gráfico acima fora dos Estados Unidos.
dados_sUS = dados %>%
filter(company_location != 'US') %>%
group_by(company_location) %>%
summarise(N = n()) %>%
mutate(num_employee.tooltip = paste("Total de empresas:", N),
Tooltip.header = "") %>%
ungroup()
dados_sUS %>%
select(company_location, N) %>%
mutate(Porcentagem = round(N / sum(N), 3)) %>%
arrange(desc(Porcentagem))
## # A tibble: 71 × 3
## company_location N Porcentagem
## <fct> <int> <dbl>
## 1 GB 172 0.241
## 2 CA 87 0.122
## 3 ES 77 0.108
## 4 IN 58 0.081
## 5 DE 56 0.078
## 6 FR 34 0.048
## 7 BR 15 0.021
## 8 AU 14 0.02
## 9 GR 14 0.02
## 10 PT 14 0.02
## # ℹ 61 more rows
op = options(gvis.plot.tag = 'chart')
G = gvisGeoChart(dados_sUS, "company_location", "N",
options=list(projection="kavrayskiy-vii",
width=800, height=400))
plot(G)
Note que, fora dos Estados Unidos, a maioria das empresas estão situadas na Inglaterra (24,1%), Canadá (12,2%), Espanha (10,8%), Índia (8,1%), Alemanha (7,8%) e França (4,8%).
Onde se pagam os maiores salários médios?
df = dados %>%
group_by(company_location) %>%
dplyr::summarise(mean_salary = mean(salary_in_usd))
df %>% arrange(desc(mean_salary))
## # A tibble: 72 × 2
## company_location mean_salary
## <fct> <dbl>
## 1 IL 271446.
## 2 PR 167500
## 3 US 151822.
## 4 RU 140333.
## 5 CA 131918.
## 6 NZ 125000
## 7 BA 120000
## 8 IE 114943.
## 9 JP 114127.
## 10 SE 105000
## # ℹ 62 more rows
op = options(gvis.plot.tag = 'chart')
G = gvisGeoChart(df, "company_location", "mean_salary",
options=list(projection="kavrayskiy-vii",
width=800, height=400))
plot(G)
Note que o país em que se paga o maior salário médio (em média 271446,00 dólares) para profissionais de Data Science é Israel (IL), seguido por Porto Rico (PR) (em média 167500,00 dólares) e Estados Unidos, que em média paga 151822,01 dólares para esses profissionais. No Brasil, o salário médio pago é de 40579,20 dólares.
Qual o valor que separa os 10% maiores salarios recebidos e qual a relação com o nível de experiência do profissional?
dados %>%
summarise(top10 = quantile(dados$salary_in_usd, prob = 0.9))
## top10
## 1 219000
Podemos observar que o salário que separa os 10% maiores salários é de 219000,00 dólares. Qual o nível de experiência dos empregados que ganham mais que esse valor?
dados %>%
group_by(experience_level,top10Salary) %>%
dplyr::summarise(N=n())%>%
mutate(Porcentagem = round(N / sum(N), 3))
## # A tibble: 8 × 4
## # Groups: experience_level [4]
## experience_level top10Salary N Porcentagem
## <fct> <fct> <int> <dbl>
## 1 EN no 315 0.984
## 2 EN yes 5 0.016
## 3 EX no 75 0.658
## 4 EX yes 39 0.342
## 5 MI no 784 0.974
## 6 MI yes 21 0.026
## 7 SE no 2206 0.877
## 8 SE yes 310 0.123
dados %>%
group_by(experience_level,top10Salary) %>%
dplyr::summarise(N=n()) %>%
ggplot(aes(fill=top10Salary, y=N, x=experience_level))+
geom_bar(position="stack", stat="identity")+
xlab('Nível de Experiência')+
ylab('Frequência')+
theme_pubclean()
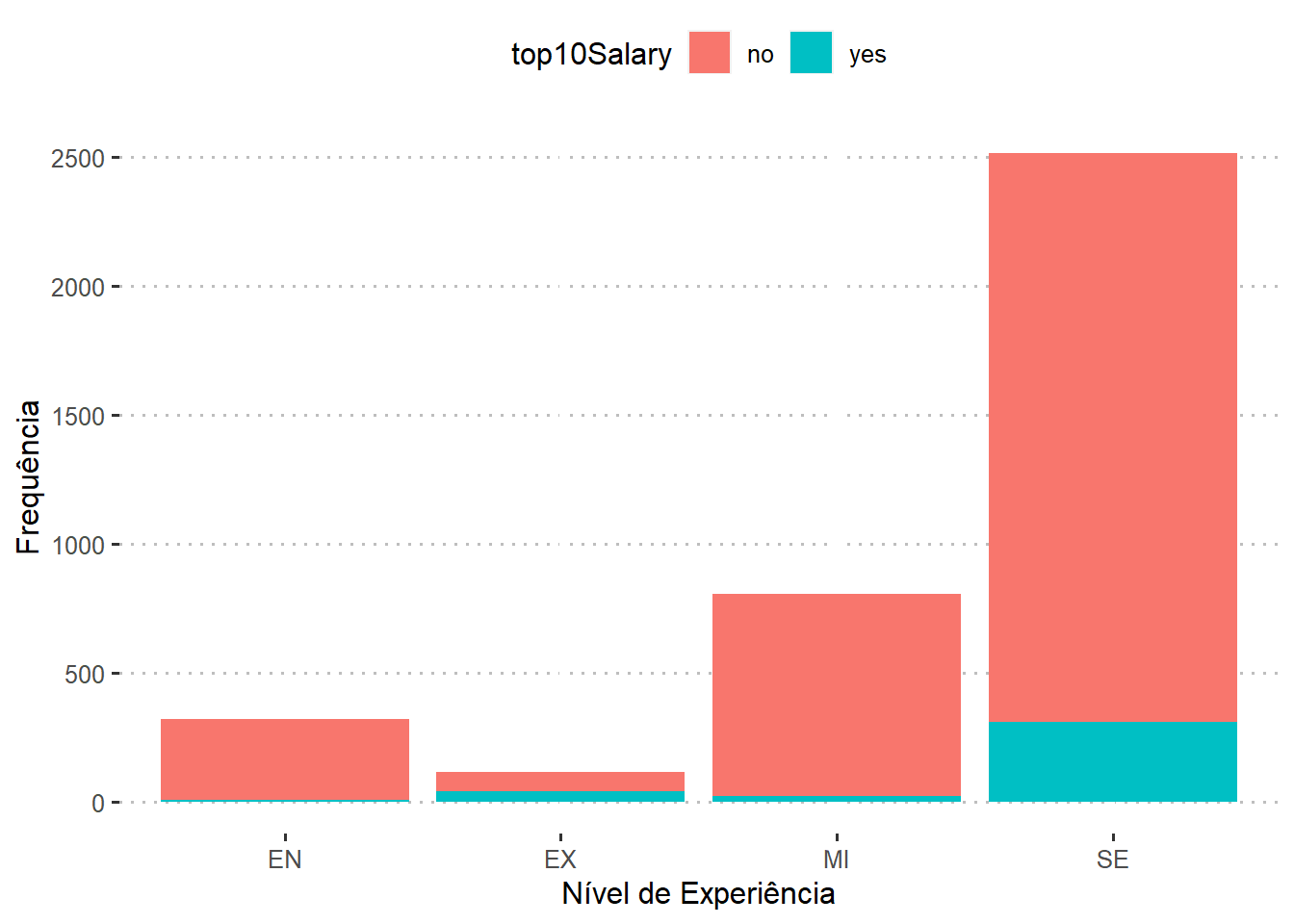
Observe que, para a categoria júnior (EN), apenas 1,6% (5 observações) dos empregados que recebem salários na faixa dos 10% maiores. Para a categoria pleno (MI), 2,6% (21 observações) recebem salários nessa faixa, enquanto que, para as categorias sênior (SE) e executivo (EX), essa faixa salarial representa 12,3% e 34,2% dos salários recebidos, respectivamente.
Qual a relação entre os maiores salários com o tipo de contrato do profissional?
dados %>%
group_by(employment_type,top10Salary) %>%
dplyr::summarise(N=n())%>%
mutate(Porcentagem = round(N / sum(N), 3))
## # A tibble: 6 × 4
## # Groups: employment_type [4]
## employment_type top10Salary N Porcentagem
## <fct> <fct> <int> <dbl>
## 1 CT no 8 0.8
## 2 CT yes 2 0.2
## 3 FL no 10 1
## 4 FT no 3345 0.9
## 5 FT yes 373 0.1
## 6 PT no 17 1
dados %>%
group_by(employment_type,top10Salary) %>%
dplyr::summarise(N=n()) %>%
ggplot(aes(fill=top10Salary, y=N, x=employment_type))+
geom_bar(position="stack", stat="identity")+
xlab('Tipo de contrato de trabalho')+
ylab('Frequência')+
theme_pubclean()
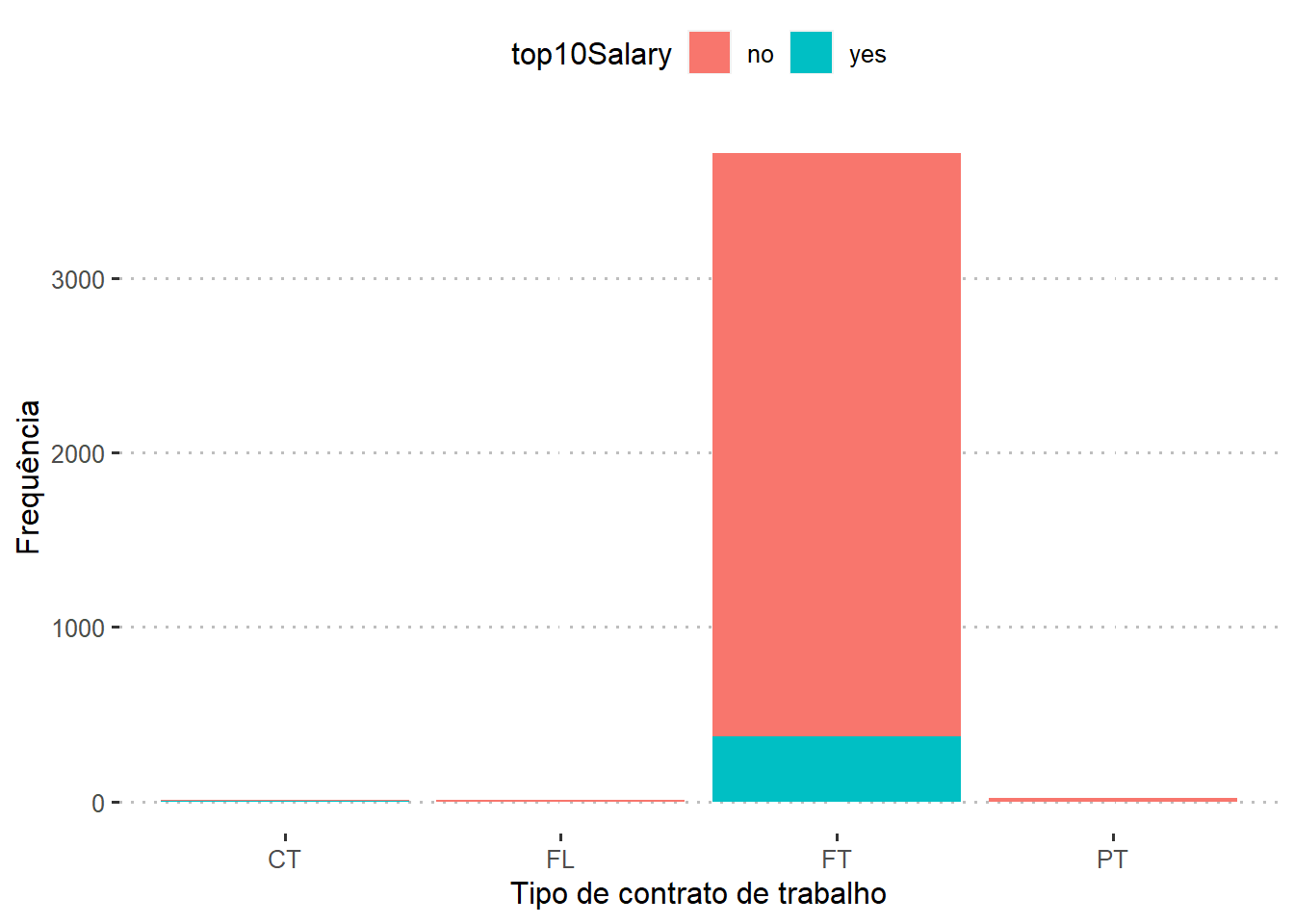
Observe que, para o tipo de trabalho por contrato (CT), 20% dos empregados recebem salários na faixa dos 10% maiores. Já para quem trabalha em regime de tempo integral (FT), 10% recebem salários nessa faixa. Para quem trabalha em regime de meio período (PT) e Freelance (FL), nenhum funcionário recebe salários na faixa dos 10% maiores.
Qual a relação entre os maiores salários com modalidade de trabalho do profissional?
dados %>%
group_by(remote_ratio,top10Salary) %>%
dplyr::summarise(N=n())%>%
mutate(Porcentagem = round(N / sum(N), 3))
## # A tibble: 6 × 4
## # Groups: remote_ratio [3]
## remote_ratio top10Salary N Porcentagem
## <int> <fct> <int> <dbl>
## 1 0 no 1698 0.883
## 2 0 yes 225 0.117
## 3 50 no 182 0.963
## 4 50 yes 7 0.037
## 5 100 no 1500 0.913
## 6 100 yes 143 0.087
dados %>%
group_by(remote_ratio,top10Salary) %>%
dplyr::summarise(N=n()) %>%
ggplot(aes(fill=top10Salary, y=N, x= factor(remote_ratio, labels = c('Presencial', 'Híbrido', 'Remoto'))))+
geom_bar(position="stack", stat="identity")+
xlab('Regime de trabalho')+
ylab('Frequência')+
theme_pubclean()
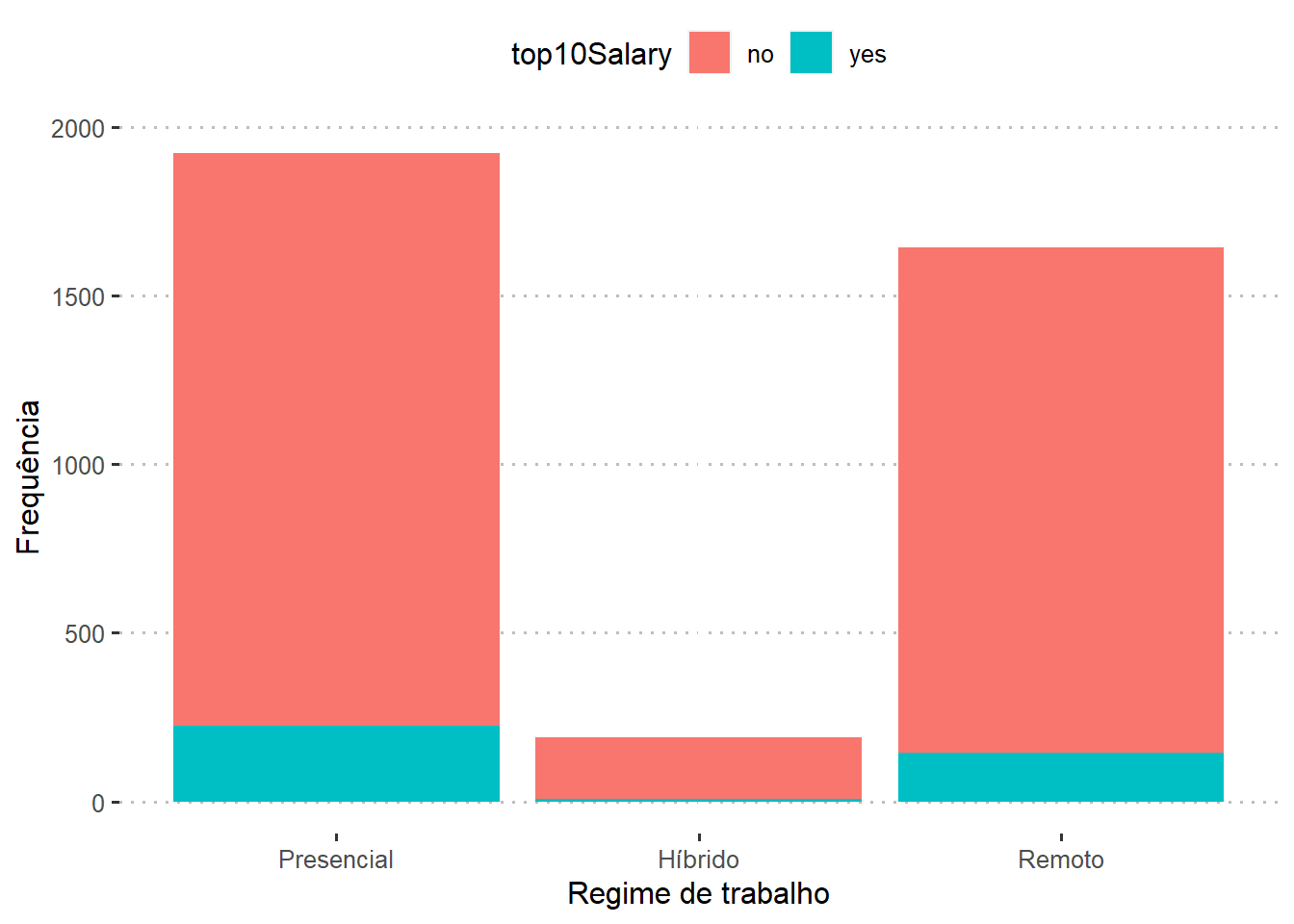
Aparentemente o regime de trabalho não possui relação com o fato de se ganhar salários na faixa dos 10% maiores.
Qual a relação entre os maiores salários com o tamanho da empresa?
dados %>%
group_by(company_size,top10Salary) %>%
dplyr::summarise(N=n())%>%
mutate(Porcentagem = round(N / sum(N), 3))
## # A tibble: 6 × 4
## # Groups: company_size [3]
## company_size top10Salary N Porcentagem
## <fct> <fct> <int> <dbl>
## 1 L no 411 0.905
## 2 L yes 43 0.095
## 3 M no 2825 0.896
## 4 M yes 328 0.104
## 5 S no 144 0.973
## 6 S yes 4 0.027
dados %>%
group_by(company_size,top10Salary) %>%
dplyr::summarise(N=n()) %>%
ggplot(aes(fill=top10Salary, y=N, x= company_size))+
geom_bar(position="stack", stat="identity")+
xlab('Tamanho da empresa')+
ylab('Frequência')+
theme_pubclean()
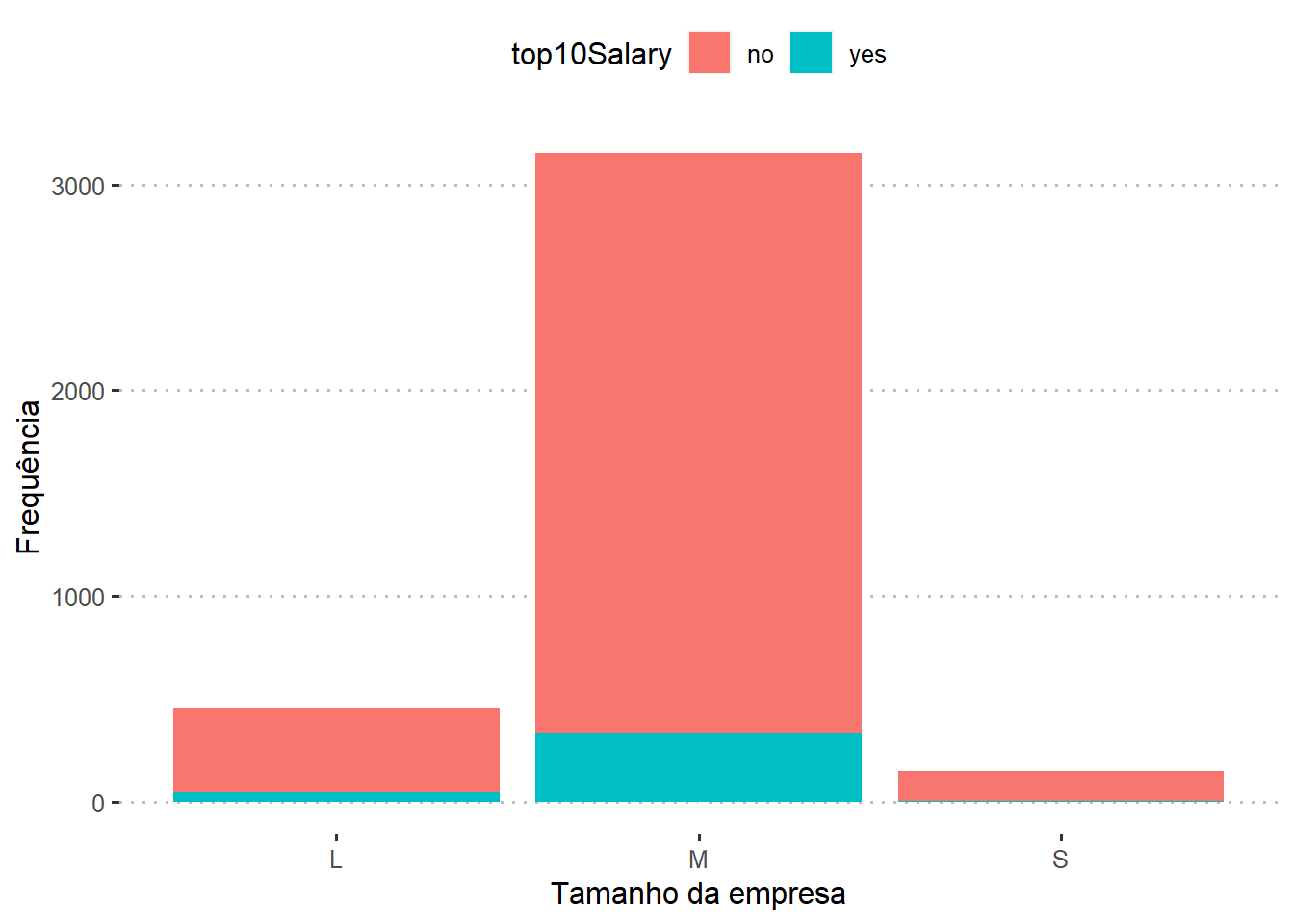
Observe que a grande minoria dos funcionários das empresas, independente do tamanho, recebem salários na faixa dos 10% maiores. Aparentemente o tamanho da empresa não influencia no pagamento de salários nessa faixa.
Conclusão
A área de ciência de dados oferece uma gama diversificada de oportunidades de trabalho, com salários variados, dependendo de vários fatores.Baseados na análise exploratória de dados (EDA), temos as seguintes informações acerca dos salários de profissionais de Data Science em diferentes regiões:
- A maioria dos profissionais possuem nível de experiência sênior e trabalham em horário integral.
- A grande maioria dos profissionais ganham menos de 200000,00 dólares. O salário médio fica em torno de 137570,00 dólares.
- Os cargos de Data Engineer, Data Scientist, Data Analyst e Machine Learning Engineer são os mais frequentes no mercado de trabalho.
- A maioria das empresas são de médio porte. Além disso, o tamanho da empresa nem sempre determina a faixa salarial, com empresas de médio porte oferecendo salários competitivos para atrair trabalhadores qualificados.
- A experiência do profissional, aparentemente é um fator importante na definição do salário. Profissionais da categoria sênior e executivo tendem a ganhar salários mais altos.
- A grande maioria das empresas estão situadas nos Estados Unidos. A grande maioria dos empregados residem neste país. Porém, os maiores salários, em média, são pagos por empresas localizadas em Israel e Porto Rico.
- Os 10% maiores salários são pagos, em sua maioria, a profissionais das categorias sênior e executivo que trabalham por contrato ou em tempo integral.
- Aparentemente, o regime de trabalho (presencial, remoto ou híbrido) não impacta significativamente na determinação do salário.
Com o uso de técnicas de EDA, tivemos descobertas que enfatizam a importância de alguns fatores relacionados ao trabalho na determinação da remuneração e que podem orientar aspirantes a profissionais de dados na negociação de pacotes salariais melhores.
Introdução à Mineração de Dados
Semestre 2024-1
Disciplina eletiva oferecida pelo Departamento de Estatística.