Pré-processamento usando a base de dados Space Titanic
Exemplo do uso de técnicas de pré-processamento no conjunto de dados “Space Titanic”, de forma a garantir resultados mais precisos e confiáveis.
 Crédito da imagem: Joel Filipe, Richard Gatley e ActionVance
Crédito da imagem: Joel Filipe, Richard Gatley e ActionVance
Olá pessoal, beleza?
Bem-vindo ao ano de 2912, onde suas habilidades em ciência de dados são necessárias para resolver um mistério cósmico. Recebemos uma transmissão de quatro anos-luz de distância e as coisas não parecem boas.
A espaçonave Titanic foi um transatlântico interestelar lançado há um mês. Com quase 13.000 passageiros a bordo, a embarcação partiu em sua viagem inaugural transportando emigrantes de nosso sistema solar para três exoplanetas recém-habitáveis orbitando estrelas próximas.
Ao contornar Alpha Centauri a caminho de seu primeiro destino - o tórrido 55 Cancri E - a incauta nave espacial Titanic colidiu com uma anomalia do espaço-tempo escondida dentro de uma nuvem de poeira. Infelizmente, ele teve um destino semelhante ao de seu homônimo de 1000 anos antes. Embora a nave tenha permanecido intacta, quase metade dos passageiros foram transportados para uma dimensão alternativa!
Para ajudar as equipes de resgate e recuperar os passageiros perdidos, você é desafiado a prever quais passageiros foram transportados pela anomalia usando registros recuperados do sistema de computador danificado da espaçonave.
Ajude a salvá-los e mude a história!
O conjunto de dados “Space Titanic” disponível no Kaggle é uma coleção de informações sobre uma hipotética tragédia espacial em uma nave chamada “Starship Titanic” e sua tarefa é prever se um passageiro foi transportado para uma dimensão alternativa durante a colisão da espaçonave com a anomalia do espaço-tempo. Para ajudá-lo a fazer essas previsões, você recebe um conjunto de registros pessoais recuperados do sistema de computador danificado da nave.
Sobre os dados
O conjunto de dados refere-se aos registros pessoais de cerca de 8700 passageiros, mensurados nas seguintes características:
-
PassengerId - Um ID exclusivo para cada passageiro. Cada Id assume a forma gggg_pp onde gggg indica um grupo com o qual o passageiro está viajando e pp é seu número dentro do grupo. As pessoas em um grupo geralmente são membros da família, mas nem sempre.
-
HomePlanet - O planeta do qual o passageiro partiu, normalmente seu planeta de residência permanente.
-
CryoSleep - Indica se o passageiro optou por ser colocado em animação suspensa durante a viagem. Os passageiros em sono criogênico estão confinados em suas cabines.
-
Cabine - O número da cabine onde o passageiro está hospedado. Assume a forma deck/num/side, onde side pode ser P para bombordo ou S para estibordo.
-
Destination - O planeta para o qual o passageiro irá desembarcar.
-
Idade - A idade do passageiro.
-
VIP - Se o passageiro pagou pelo serviço VIP especial durante a viagem.
-
RoomService, FoodCourt, ShoppingMall, Spa, VRDeck - Valor que o passageiro pagou em cada uma das muitas comodidades de luxo do Titanic.
-
Nome - O nome e o sobrenome do passageiro.
-
Transported - Se o passageiro foi transportado para outra dimensão. Este é o alvo, a coluna que você está tentando prever.
Apesar desse conjunto de dados destinar-se ao aprendizado de máquina supervisionado, faremos, neste sript, apenas a parte de pré-processamento, incluindo algumas análises exploratórias. Tentaremos responder às seguintes questões:
- De onde vieram os passageiros e qual a relação disso com ser transportado ou não?
- Em que cabine estavam os passageiros e qual a relação disso com ser transportado ou não?
- Para onde iriam os passageiros e qual a relação disso com ser transportado ou não?
- Quem estava sozinho e quem estava em grupo?
- Estar em sono profundo era uma boa ideia?
- Passageiros VIP tem menor risco de ser transportado?
- Que fatores ajudaram alguém a não ser transportado?
Pacotes utilizados
load <- function(pkg){
new.pkg <- pkg[!(pkg %in% installed.packages()[, "Package"])]
if (length(new.pkg))
install.packages(new.pkg, dependencies = TRUE)
sapply(pkg, require, character.only = TRUE)
}
## Pacotes utilizados nessa análise
packages <- c("tidyverse",'tidymodels', 'janitor', 'ggpubr', 'funModeling', 'ggalluvial', 'vip', 'skimr', 'VIM', 'patchwork')
load(packages)
## tidyverse tidymodels janitor ggpubr funModeling ggalluvial
## TRUE TRUE TRUE TRUE TRUE TRUE
## vip skimr VIM patchwork
## TRUE TRUE TRUE TRUE
Leitura dos dados
## Leitura dos dados
dados = read_csv("train.csv") %>% mutate_if(is.character, as.factor)
## Rows: 8693 Columns: 14
## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: ","
## chr (5): PassengerId, HomePlanet, Cabin, Destination, Name
## dbl (6): Age, RoomService, FoodCourt, ShoppingMall, Spa, VRDeck
## lgl (3): CryoSleep, VIP, Transported
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
dados %>% head()
## # A tibble: 6 × 14
## PassengerId HomePlanet CryoSleep Cabin Destination Age VIP RoomService
## <fct> <fct> <lgl> <fct> <fct> <dbl> <lgl> <dbl>
## 1 0001_01 Europa FALSE B/0/P TRAPPIST-1e 39 FALSE 0
## 2 0002_01 Earth FALSE F/0/S TRAPPIST-1e 24 FALSE 109
## 3 0003_01 Europa FALSE A/0/S TRAPPIST-1e 58 TRUE 43
## 4 0003_02 Europa FALSE A/0/S TRAPPIST-1e 33 FALSE 0
## 5 0004_01 Earth FALSE F/1/S TRAPPIST-1e 16 FALSE 303
## 6 0005_01 Earth FALSE F/0/P PSO J318.5-22 44 FALSE 0
## # ℹ 6 more variables: FoodCourt <dbl>, ShoppingMall <dbl>, Spa <dbl>,
## # VRDeck <dbl>, Name <fct>, Transported <lgl>
dados %>% df_status()
## variable q_zeros p_zeros q_na p_na q_inf p_inf type unique
## 1 PassengerId 0 0.00 0 0.00 0 0 factor 8693
## 2 HomePlanet 0 0.00 201 2.31 0 0 factor 3
## 3 CryoSleep 5439 62.57 217 2.50 0 0 logical 2
## 4 Cabin 0 0.00 199 2.29 0 0 factor 6560
## 5 Destination 0 0.00 182 2.09 0 0 factor 3
## 6 Age 178 2.05 179 2.06 0 0 numeric 80
## 7 VIP 8291 95.38 203 2.34 0 0 logical 2
## 8 RoomService 5577 64.16 181 2.08 0 0 numeric 1273
## 9 FoodCourt 5456 62.76 183 2.11 0 0 numeric 1507
## 10 ShoppingMall 5587 64.27 208 2.39 0 0 numeric 1115
## 11 Spa 5324 61.24 183 2.11 0 0 numeric 1327
## 12 VRDeck 5495 63.21 188 2.16 0 0 numeric 1306
## 13 Name 0 0.00 200 2.30 0 0 factor 8473
## 14 Transported 4315 49.64 0 0.00 0 0 logical 2
Podemos observar que, com exceção das variáveis PassengerId e Transported, todas as outras possuem dados ausentes, representando, em cada uma delas, aproximadamente 2,5% das observações.
Explorando os dados
Na própria apresentação da base de dados, na descrição das variáveis, foi informado que o atributo PassengerId assume a forma gggg_pp onde gggg indica um grupo com o qual o passageiro está viajando e pp é seu número dentro do grupo. Dessa forma, vamos criar duas novas variáveis, PassGroup para o grupo e nGroup para o número do passageiro no grupo.
dados = dados %>%
separate(PassengerId, c("PassGroup", "nGroup"), sep = "_", remove = FALSE) %>%
mutate(PassGroup = as.numeric(PassGroup))
Outra variável que possui mais de uma informação embutida é a variável Cabin. Vamos separá-la em CabinDeck, representando o deck da cabine, podendo assumir os valores A, B, C, D, E, F e T, e CabinSide, podendo assumir os valores P para bombordo e S para estibordo. Também criaremos a variável CabinNum, que representa os números das cabines.
dados = dados %>%
separate(Cabin, c("CabinDeck", "CabinNum", "CabinSide"), sep = "/") %>%
mutate(CabinDeck = as.factor(CabinDeck),
CabinSide = as.factor(CabinSide))
A função ggscatmat() é uma função do pacote GGally do R que cria uma matriz de gráficos de dispersão para visualizar a relação entre várias variáveis numéricas em um conjunto de dados. Essa função é útil para visualizar rapidamente as correlações entre as variáveis, bem como para detectar padrões e tendências. No gráfico abaixo, ainda separamos os elementos de acordo com a sua classe, descrita pela variável Transported.
dados %>%
mutate(Transported = as.numeric(Transported)) %>%
select_if(is.numeric) %>%
GGally::ggscatmat(color = "Transported", corMethod = "pearson")+
theme_pubclean()
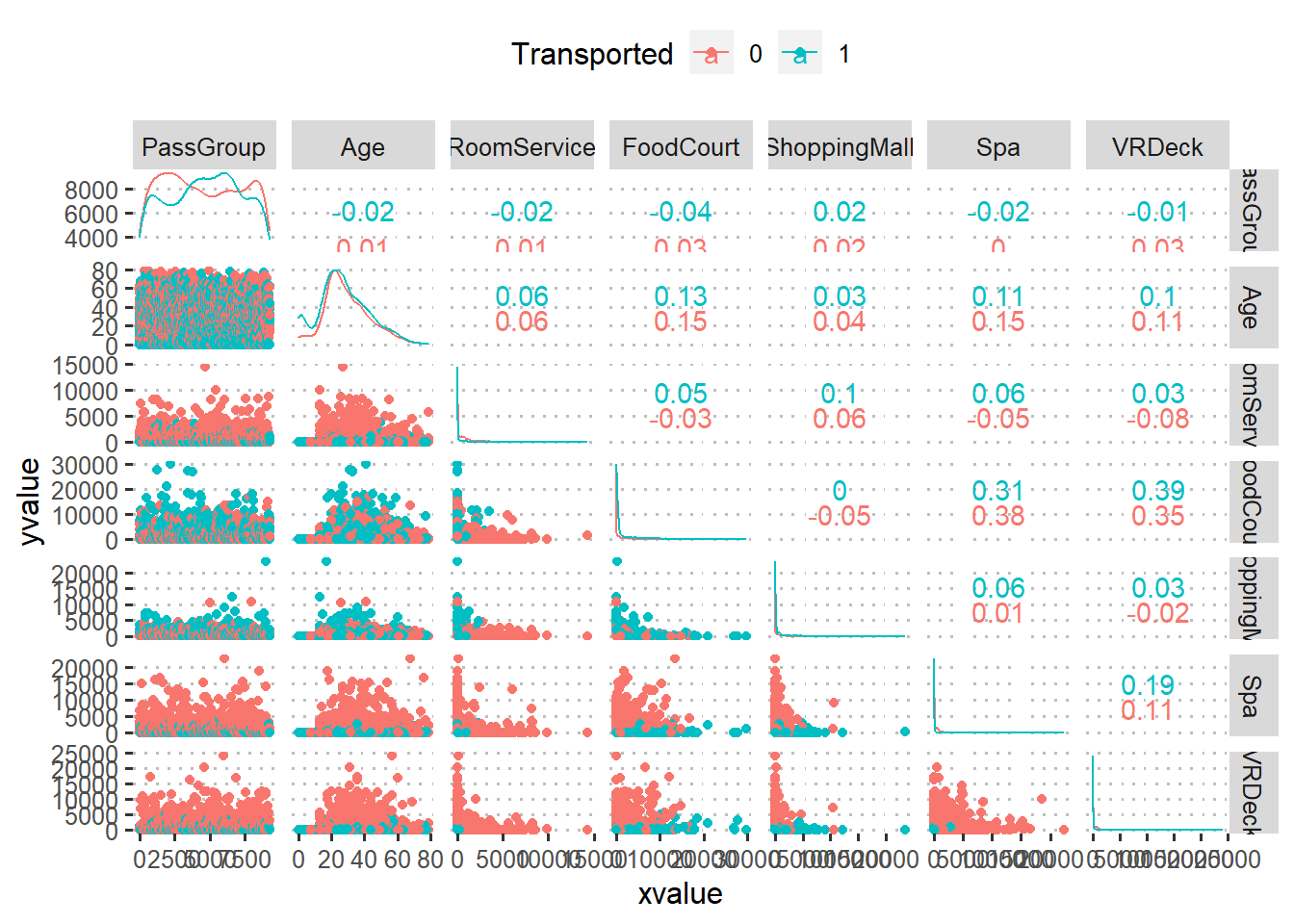
Note que fica clara a necessidade de transformações para as variáveis RoomService, FoodCourt, ShoppingMall, Spa e VRDeck, devido à sua distribuição assimétrica. Um fato interessante acontece com a variável Age:
# Age
dados %>%
ggplot(aes(x=Age, fill = Transported))+
geom_density(alpha =0.5)+
theme(legend.position='bottom')
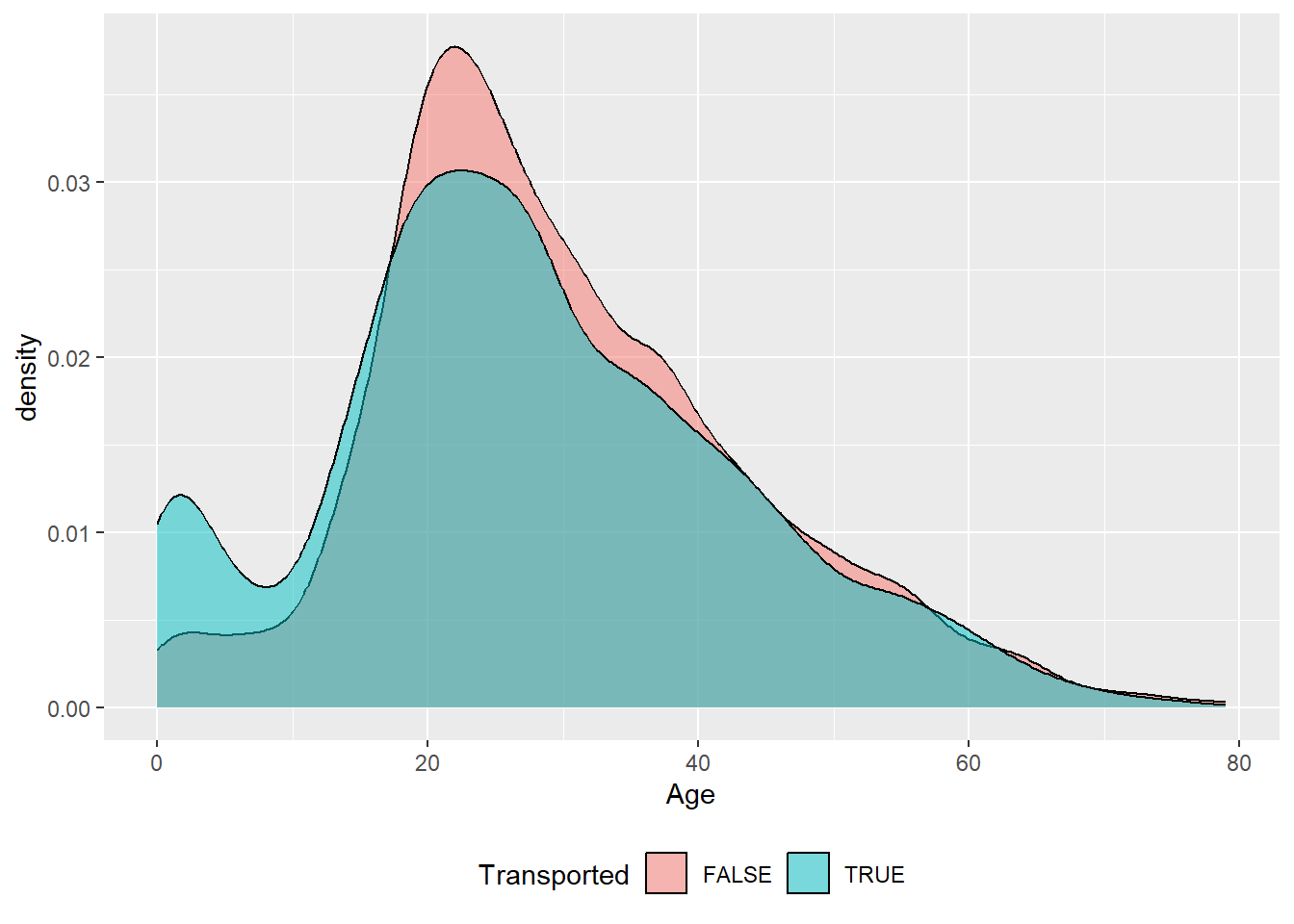
Observe que, para passageiros com idade menor de 10 anos, aproximadamente, a probabilidade do passageiro ser transportado é maior que não ser transportado. Isso sugere, talvez, a criação de um atributo captando essa informação.
De onde vieram os passageiros e qual a relação disso com ser transportado ou não?
dados %>%
ggplot(aes(x=HomePlanet))+
geom_bar(stat = "count", fill="steelblue")
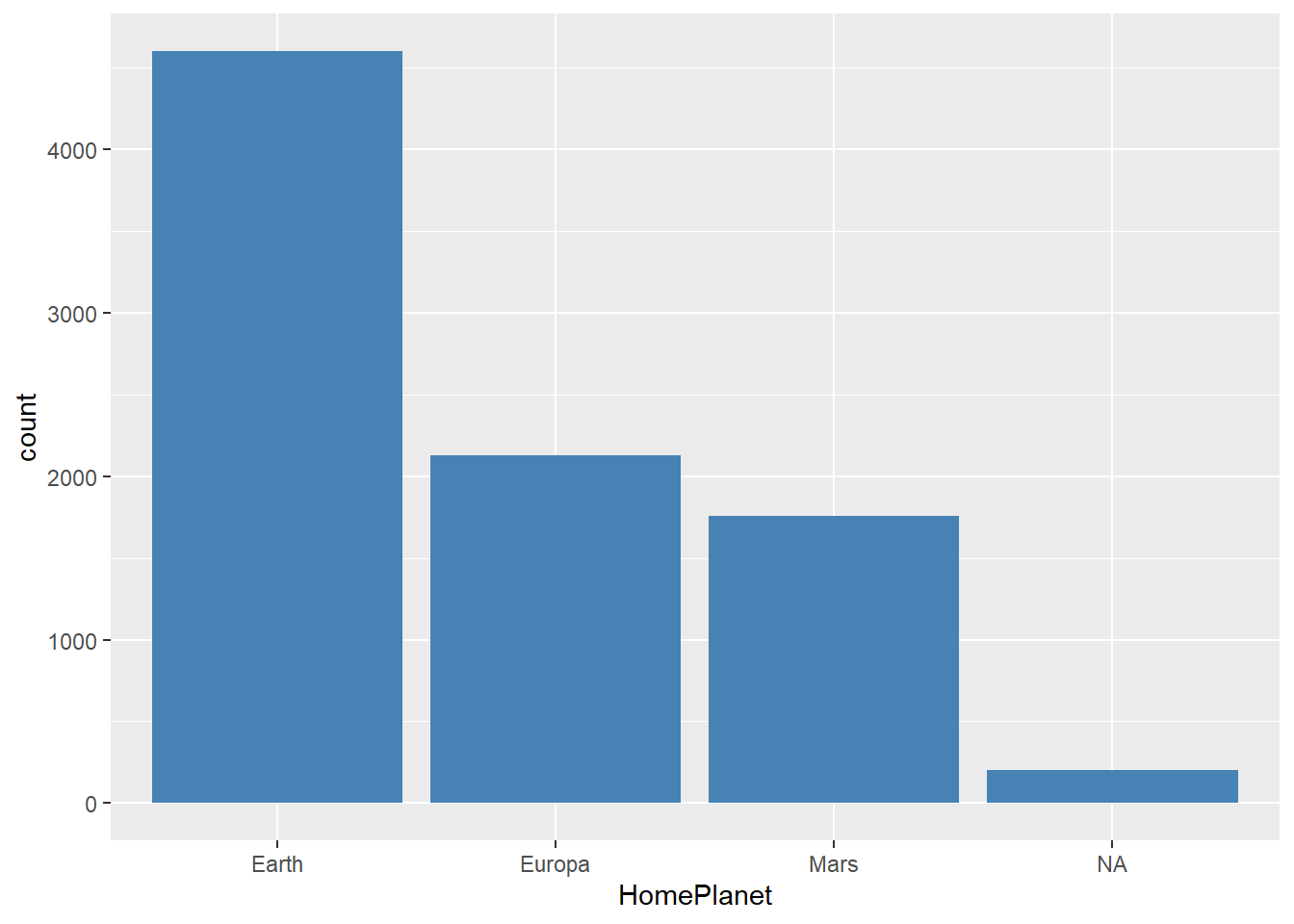
Note que a maioria dos passageiros embarcaram na Terra (Earth). Além disso, existem observações ausentes. Qual a relação da origem dos passageiros com o fato de ser transportado ou não?
dados %>%
ggplot(aes(x=HomePlanet, fill = Transported))+
geom_bar(stat = "count")+
theme(legend.position='bottom')
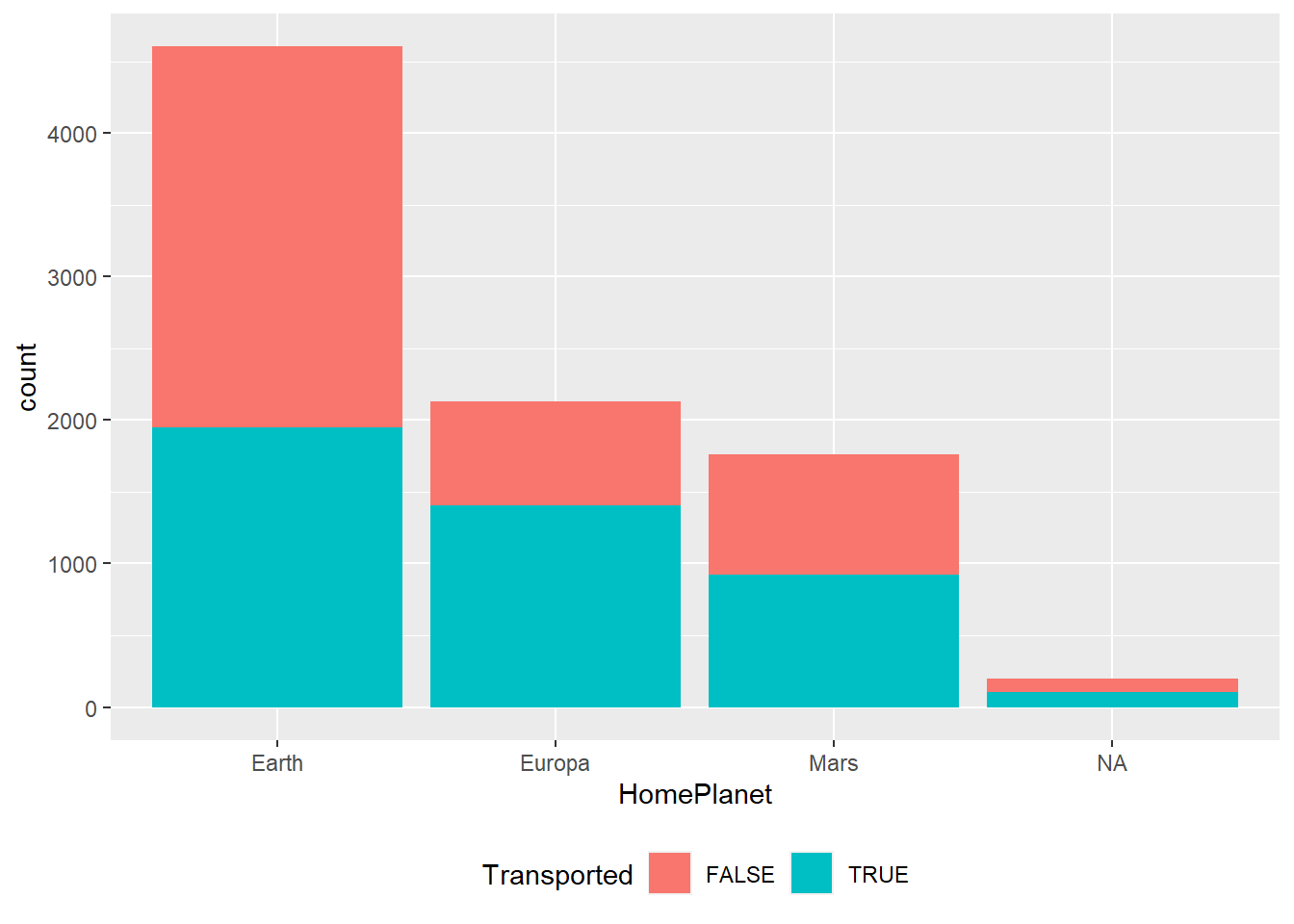
Quem veio da Terra tem menos chances de ser transportado?
Em que cabine estavam os passageiros e qual a relação disso com ser transportado ou não?
p1 = dados %>%
ggplot((aes(x=CabinDeck))) +
geom_bar(stat = 'count', fill= 'steelblue')
p2 = dados %>%
ggplot((aes(x=CabinSide))) +
geom_bar(stat = 'count', fill= 'steelblue')
p1 + p2
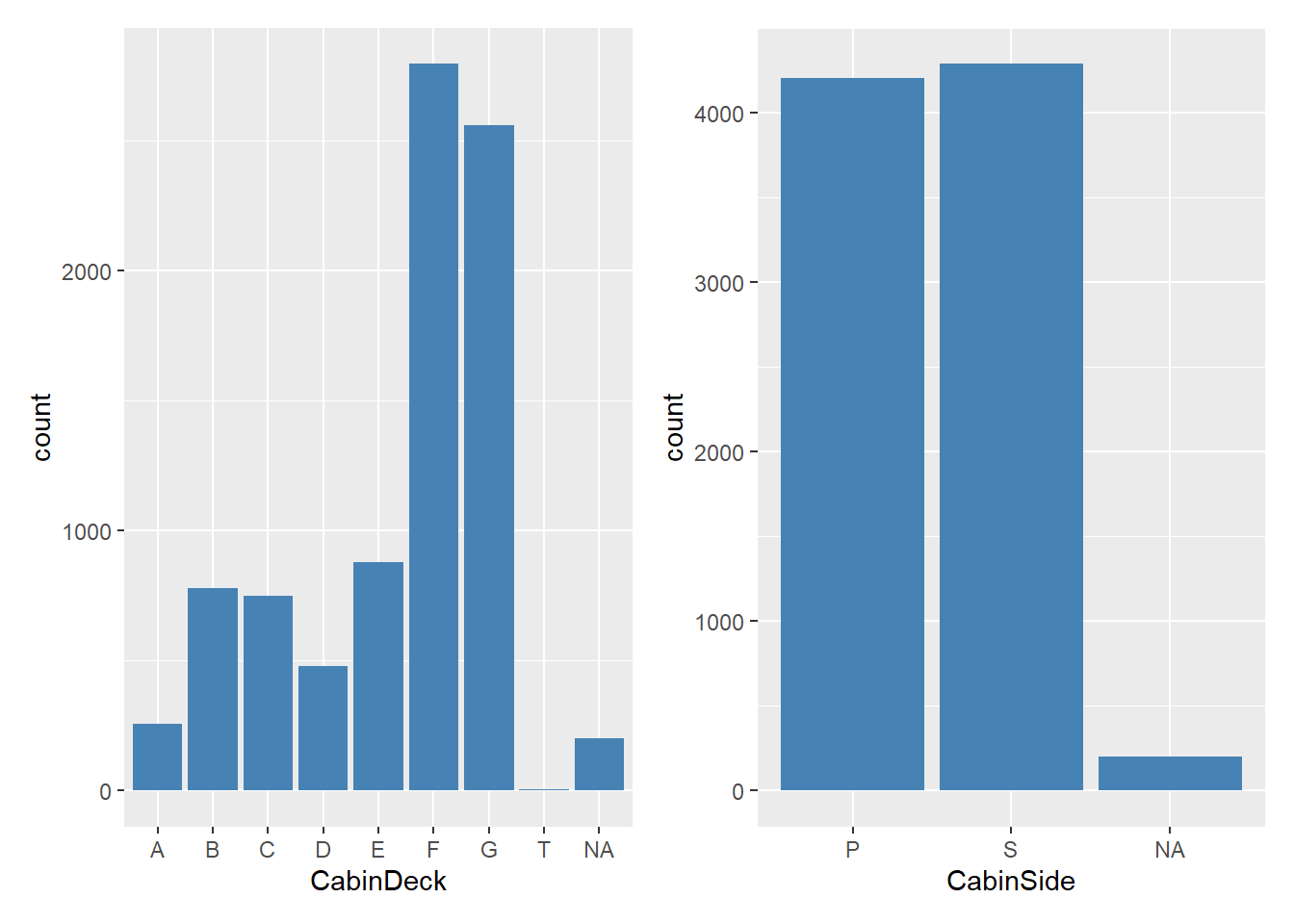
A maioria dos passageiros estavam alocados nos decks F e G. Existem observações faltantes. Os passageiros foram alocados em ambos os lados (estibordo e bombordo) de forma semelhante. Qual a relação disso com ser transportado ou não?
p1 = dados %>%
ggplot((aes(x=CabinDeck, fill = Transported))) +
geom_bar(stat = 'count')
p2 = dados %>%
ggplot((aes(x=CabinSide, fill = Transported))) +
geom_bar(stat = 'count')
p1 + p2 + plot_layout(guides = "collect") &
theme(legend.position='bottom')
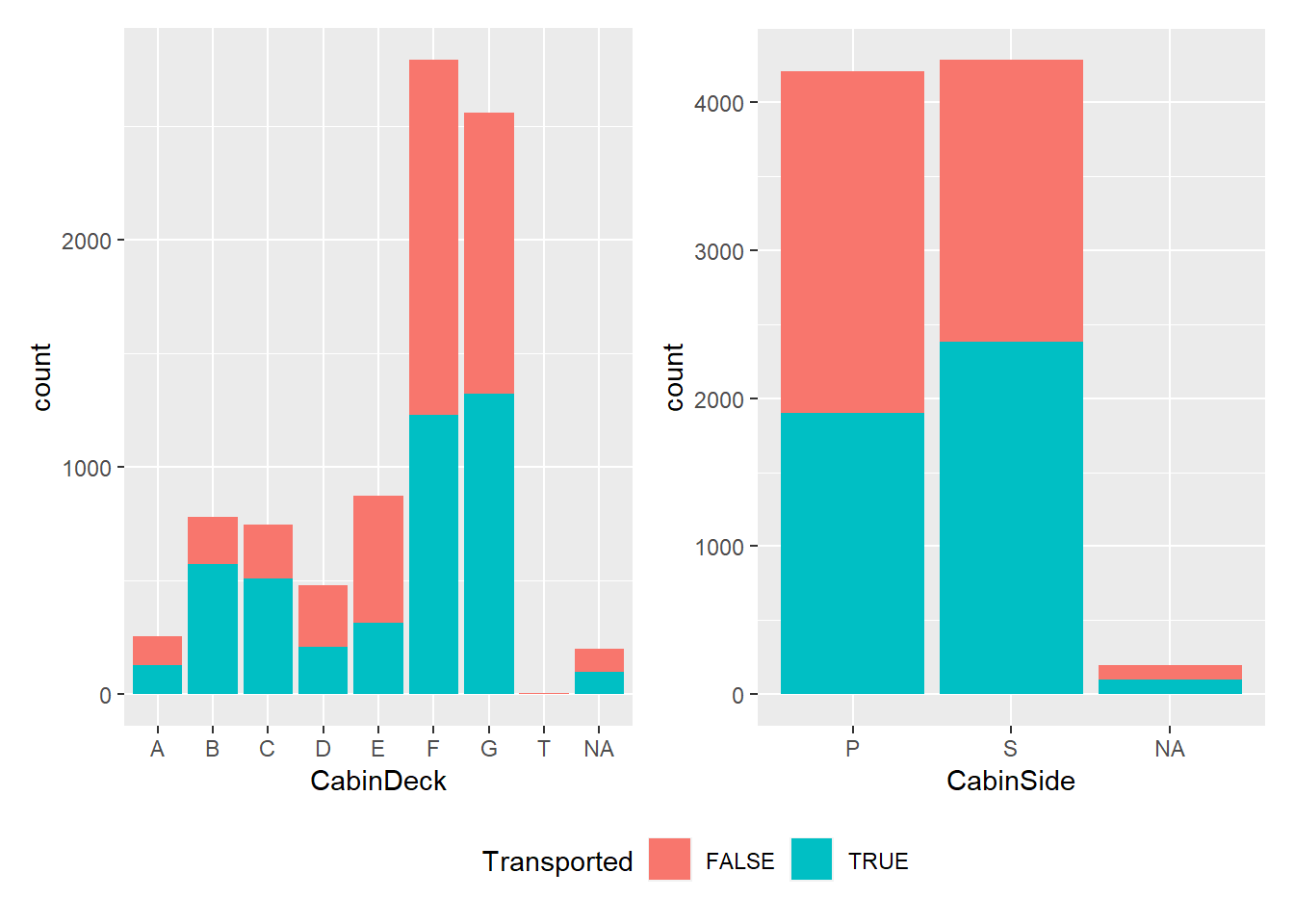
Aparentemente, quem está alocando nos decks B e C tem mais chance de ser transportado. O mesmo acontece para quem está situado no estibordo.
Para onde iriam os passageiros e qual a relação disso com ser transportado ou não?
dados %>%
ggplot((aes(x=Destination))) +
geom_bar(stat = 'count', fill= 'steelblue')
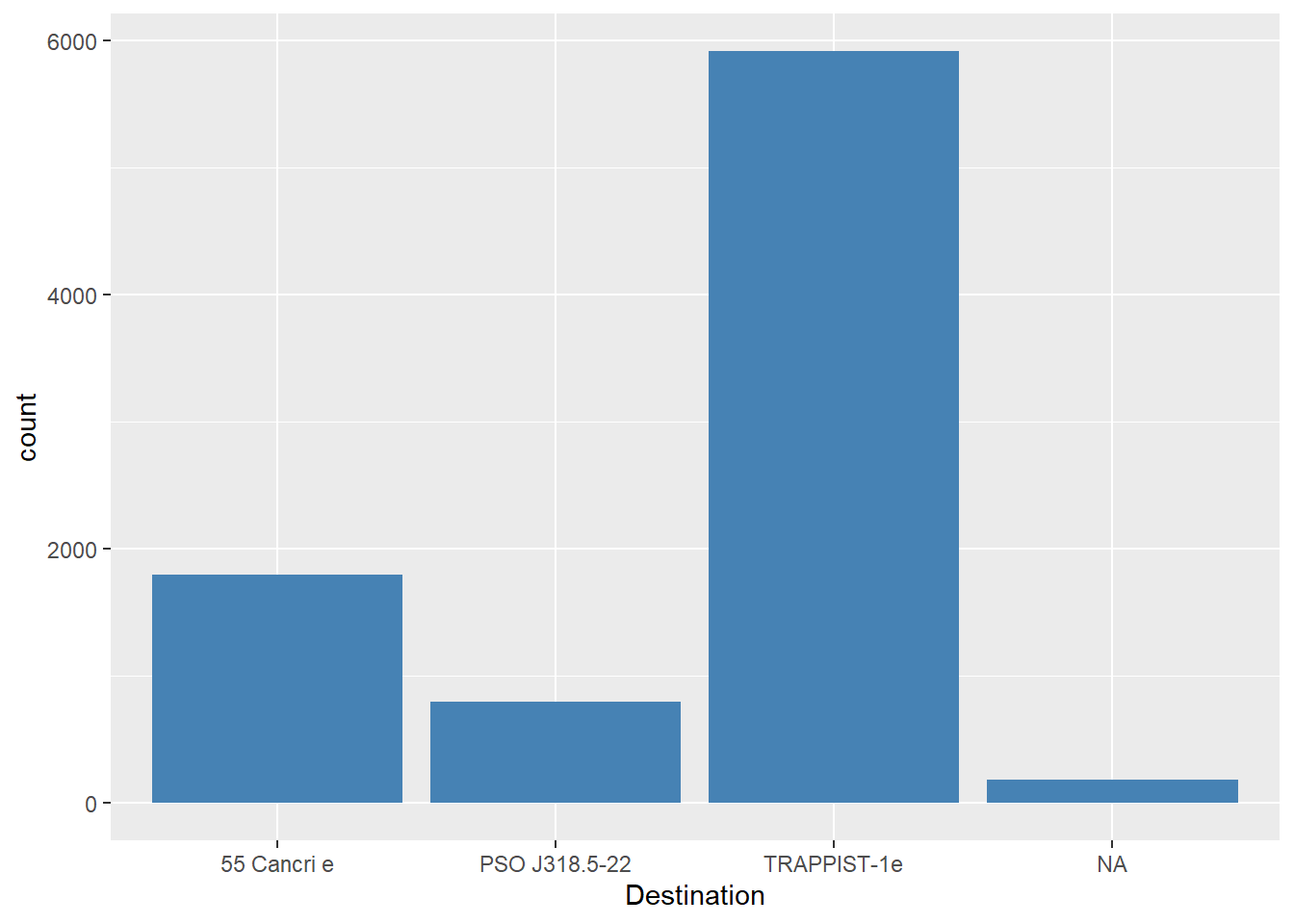
A maioria dos passageiros tinham como destino o Planeta “TRAPPIST-1e”. Qual a relação disso com ser transportado ou não?
dados %>%
ggplot((aes(x=Destination, fill= Transported))) +
geom_bar(stat = 'count')+
theme(legend.position='bottom')
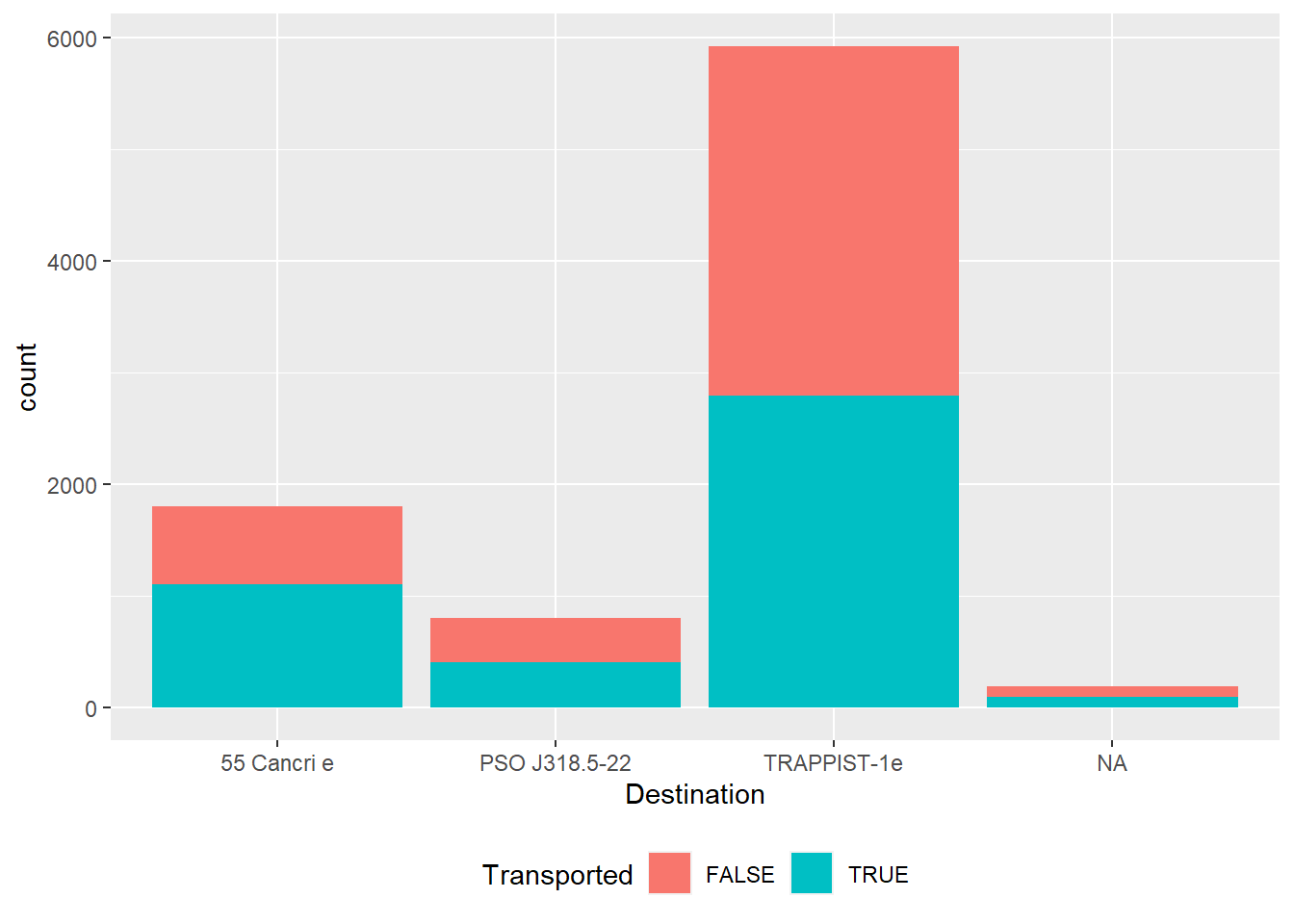
Quem iria para o Planeta “55 Cancri e” teria mais chances de ser transportado?
Quem estava sozinho e quem estava em grupo?
dados %>% add_count(PassGroup, name = "GroupSize") %>%
mutate(IsAlone = ifelse(GroupSize==1, 'yes', 'no')) %>%
ggplot(aes(x=IsAlone))+
geom_bar(stat = "count", fill= 'steelblue')
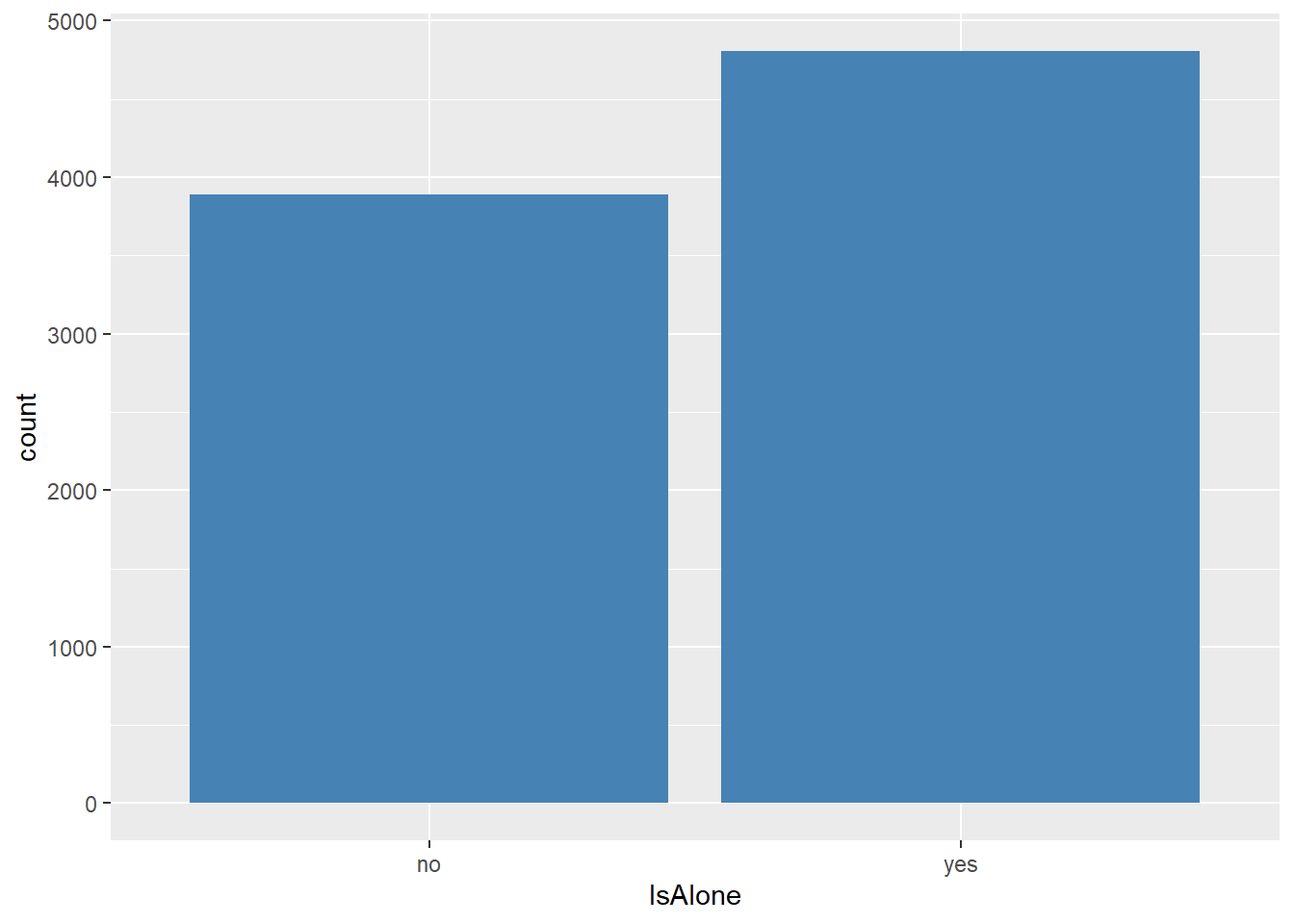
A maioria dos passageiros estavam viajando sozinho. Viajar sozinho influencia no fato de ser transportado?
dados %>% add_count(PassGroup, name = "GroupSize") %>%
mutate(IsAlone = ifelse(GroupSize==1, 'yes', 'no')) %>%
ggplot(aes(x=IsAlone, fill= Transported))+
geom_bar(stat = "count")+
theme(legend.position='bottom')
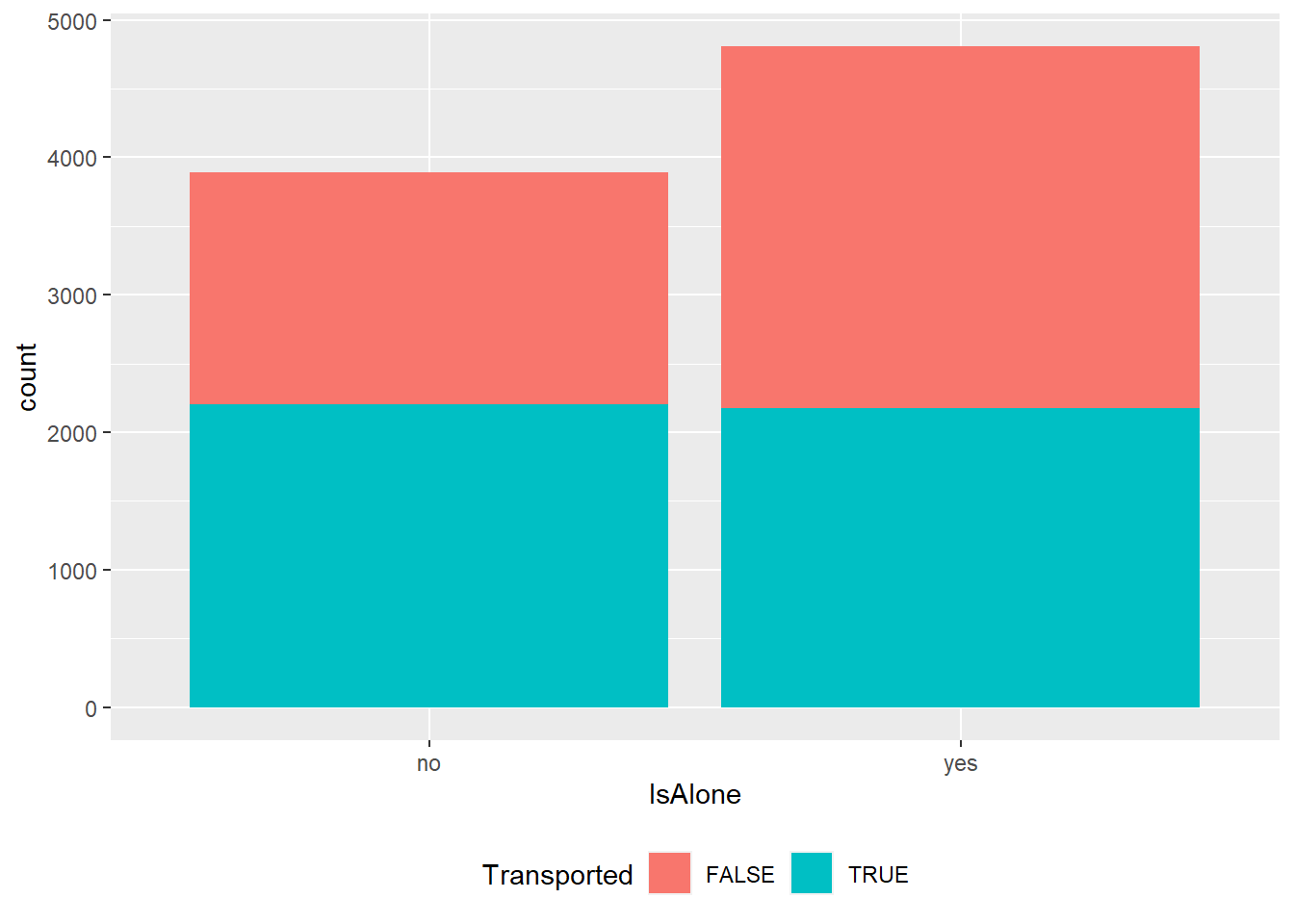
Talvez seja uma boa estar sozinho neste momento! 😃
Estar em sono profundo era uma boa ideia?

dados %>%
ggplot(aes(x=CryoSleep))+
geom_bar(stat = "count", fill= 'steelblue')
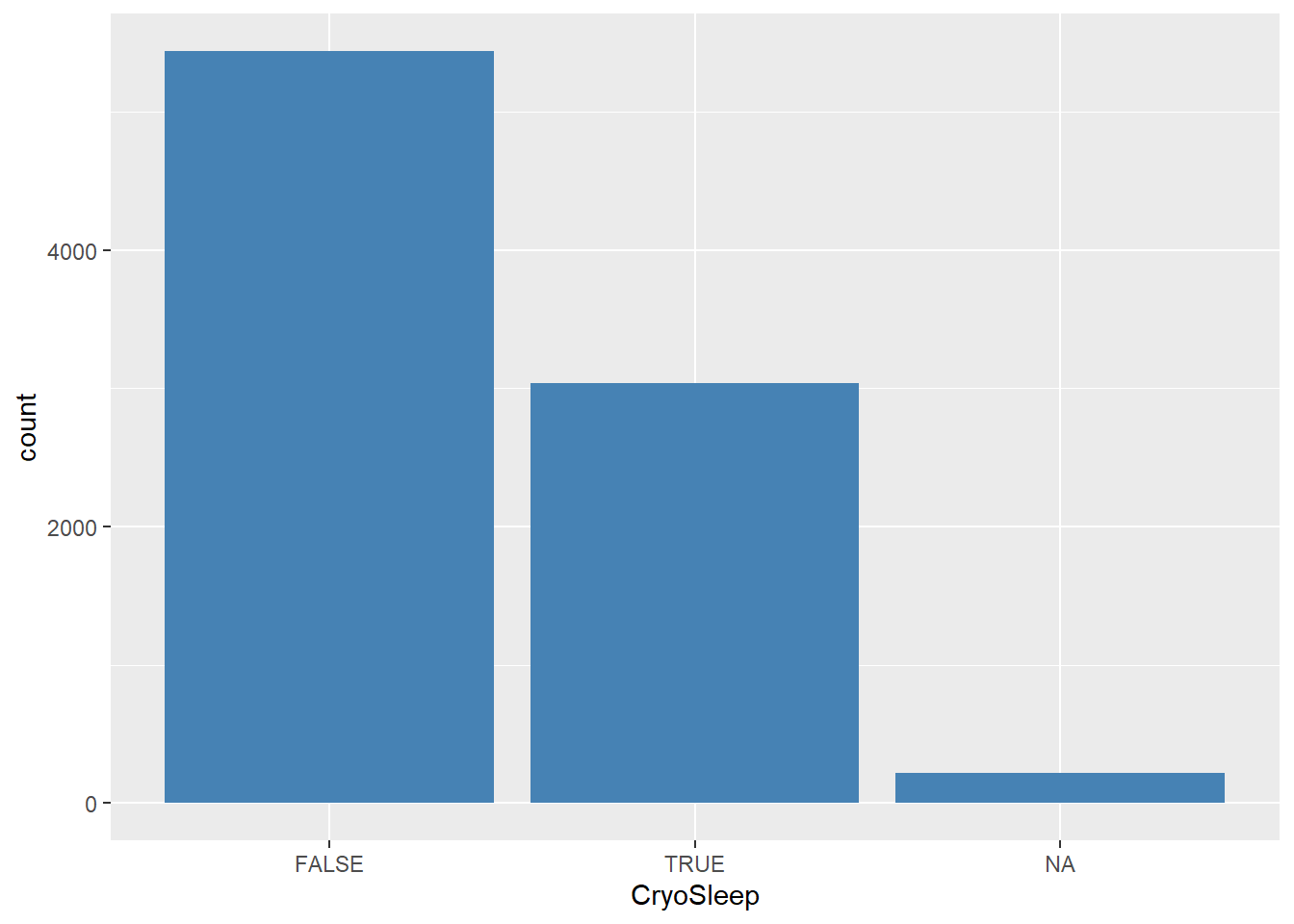
A maioria dos passageiros não estavam em sono profundo. Isso influenciou no fato de ser transportado?
dados %>%
ggplot(aes(x=CryoSleep, fill= Transported))+
geom_bar(stat = "count")+
theme(legend.position='bottom')
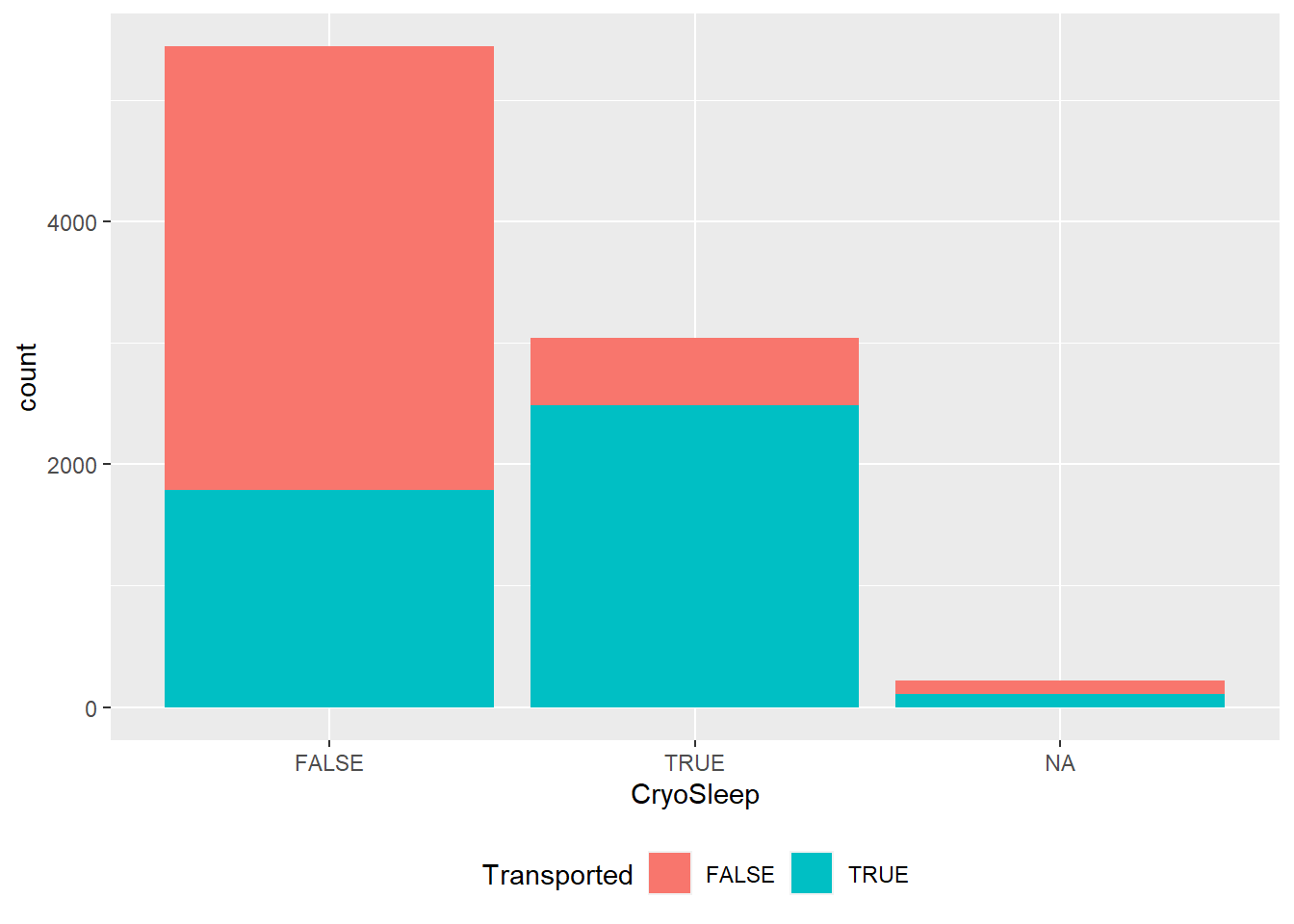
Estar em sono profundo não me pereceu ser uma boa ideia!
Passageiros VIP tem menor risco de ser transportado?
dados %>%
ggplot(aes(x=VIP))+
geom_bar(stat = "count", fill= 'steelblue')
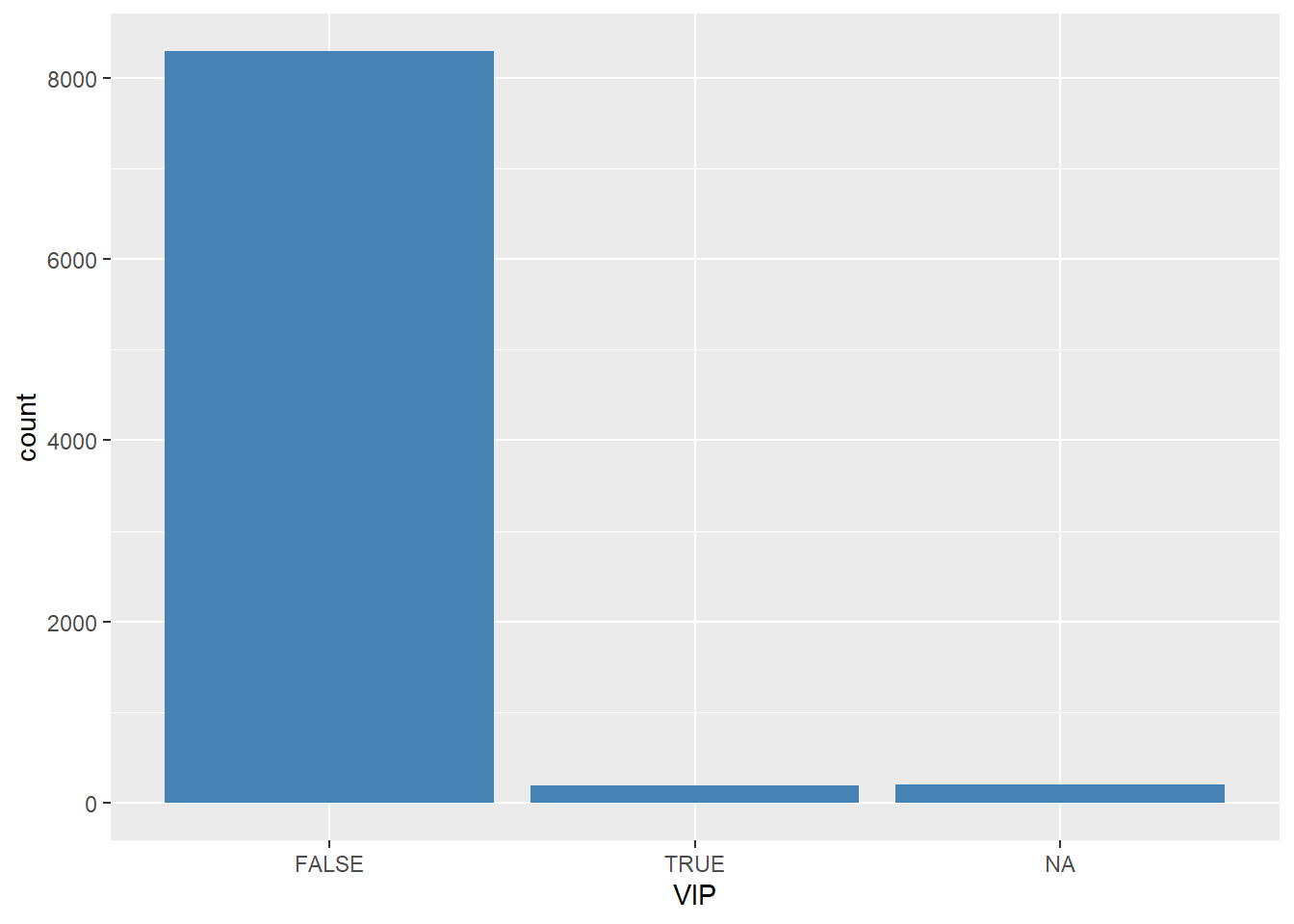
A grande maioria dos passageiros não eram VIPs. Isso influenciou no fato de ser transportado?
dados %>%
ggplot(aes(x=VIP, fill= Transported))+
geom_bar(stat = "count")+
theme(legend.position='bottom')
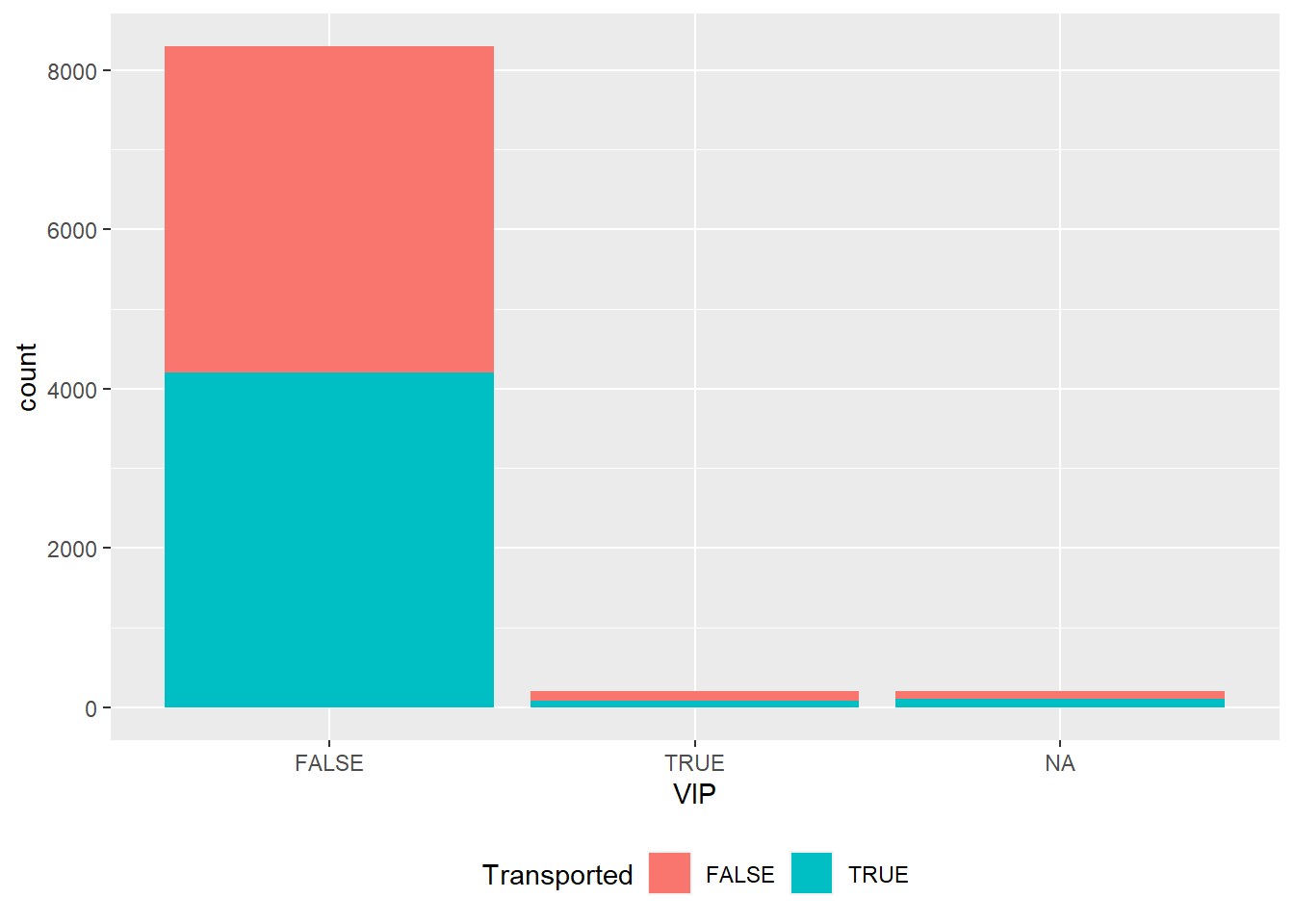
O fato de ser VIP aparentemente não possui relação com o fato de ser transportado!
Que fatores ajudaram alguém a não ser transportado?
Vamos analisar os gastos dos passageiros.
# RoomService
p1 = dados %>%
mutate(RoomService = log10(RoomService)) %>%
ggplot(aes(x=RoomService, fill = Transported))+
geom_density(alpha =0.5)
# Spa
p2 = dados %>%
mutate(Spa = log10(Spa)) %>%
ggplot(aes(x=Spa, fill = Transported))+
geom_density(alpha =0.5)
# VRDeck
p3 = dados %>%
mutate(VRDeck = log10(VRDeck)) %>%
ggplot(aes(x=VRDeck, fill = Transported))+
geom_density(alpha =0.5)
p1 + p2 + p3 + plot_layout(guides = "collect") &
theme(legend.position='bottom')
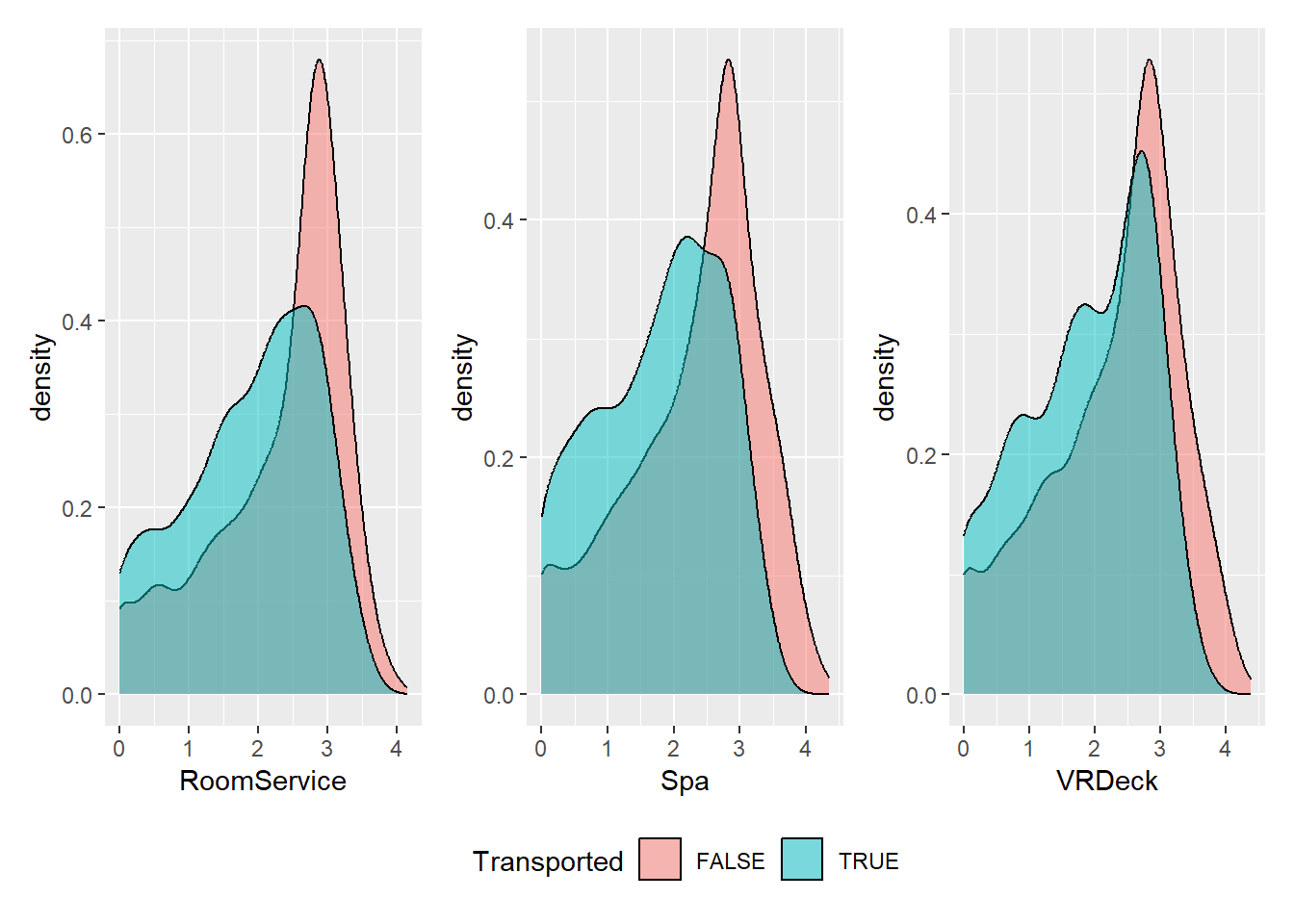
Gastos com RoomService, Spa e VRDeck aumentam a chance do passageiro não ser transportado!
# FoodCourt
p1 = dados %>%
mutate(FoodCourt = log10(FoodCourt)) %>%
ggplot(aes(x=FoodCourt, fill = Transported))+
geom_density(alpha =0.5)
# ShoppingMall
p2 = dados %>%
mutate(ShoppingMall = log10(ShoppingMall)) %>%
ggplot(aes(x=ShoppingMall, fill = Transported))+
geom_density(alpha =0.5)
p1 + p2 + plot_layout(guides = "collect") &
theme(legend.position='bottom')
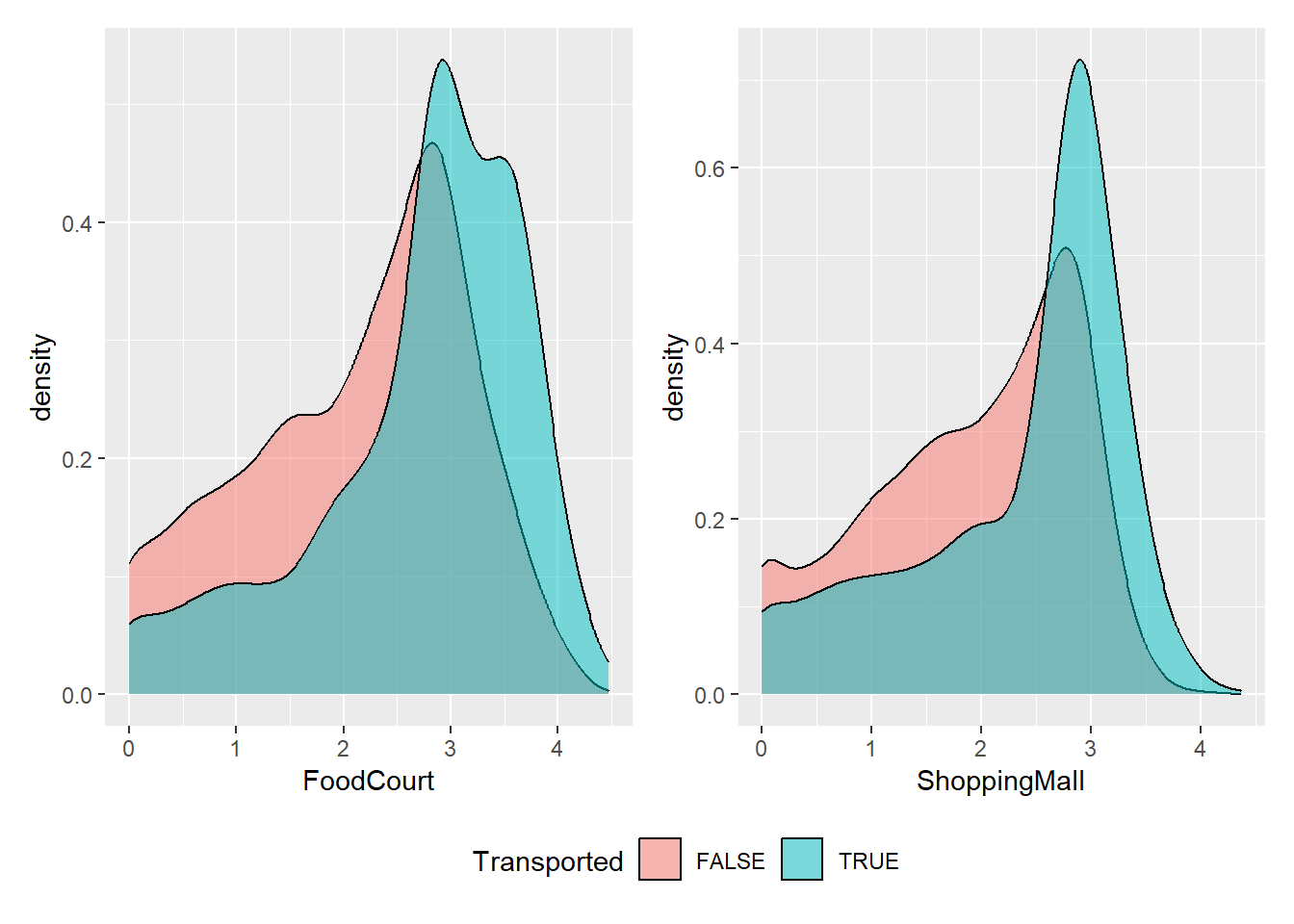
Já os gastos com FoodCourt e ShoppingMall aumentam a chance do passageiro ser transportado. Outra informação interessante pode ser obtida quando analisamos as variáveis HomePlanet e CryoSleep.
# HomePlanet e CryoSleep
dados %>%
ggplot(aes(x=HomePlanet, fill= Transported))+
geom_bar(stat = "count")+
facet_grid(~CryoSleep)+
theme(legend.position='bottom')
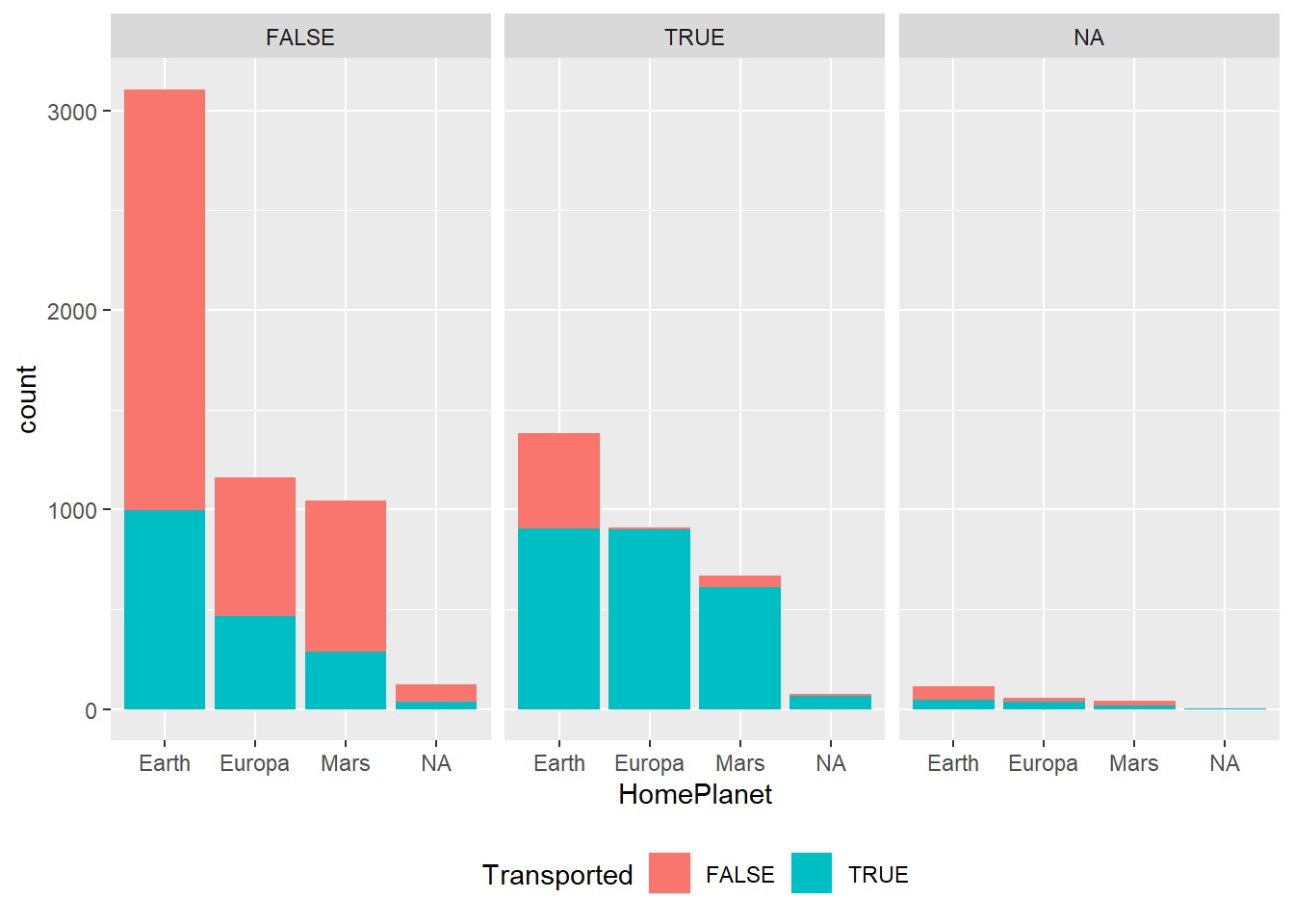
Note que, para os passageiros em suspensão profunda, o fato de não terem embarcados em Earth aumenta muito a chance de ser transportado para a dimesão alternativa!
Após a fase de exploração dos dados, algumas sugestões de feature engineering foram aparecendo:
- Criar uma variável indicando se o passageiro é menor de 14 anos, por exemplo;
- Criar uma variável indicando se o passageiro é originário da Terra;
- Criar uma variável indicando se o passageiro viajava sozinho;
- Realizar transformação (raíz quadrada) nas variáveis RoomService, Spa, VRDeck, FoodCourt e ShoppingMall.
- Criar uma variável com o total de “despesas supérfluas” (RoomService + Spa + VRDeck);
- Criar uma variável com o total de “despesas básicas” (FoodCourt + ShoppingMall);
Para evitar problema de vazamento de dados, o passo inicial de qualquer análise é separar o conjunto de treinamento, validação e teste: os dados de treinamento devem ser usados exclusivamente para treinar o modelo, enquanto os dados de validação e teste devem ser usados para avaliar sua performance. Isso evita que informações de teste ou validação sejam usadas para treinar o modelo e comprometam os resultados.
set.seed(12345)
splits = dados %>% initial_split(strata = Transported)
dados_treino = training(splits)
dados_teste = testing(splits)
Criando a variável GroupSize apenas para o conjunto de dados de treinamento:
dados_treino = dados_treino %>% add_count(PassGroup, name = "GroupSize")
Tratamento de dados faltantes
dados_treino %>% df_status()
## variable q_zeros p_zeros q_na p_na q_inf p_inf type unique
## 1 PassengerId 0 0.00 0 0.00 0 0 factor 6519
## 2 PassGroup 0 0.00 0 0.00 0 0 numeric 4949
## 3 nGroup 0 0.00 0 0.00 0 0 character 8
## 4 HomePlanet 0 0.00 133 2.04 0 0 factor 3
## 5 CryoSleep 4075 62.51 164 2.52 0 0 logical 2
## 6 CabinDeck 0 0.00 153 2.35 0 0 factor 8
## 7 CabinNum 13 0.20 153 2.35 0 0 character 1722
## 8 CabinSide 0 0.00 153 2.35 0 0 factor 2
## 9 Destination 0 0.00 131 2.01 0 0 factor 3
## 10 Age 135 2.07 133 2.04 0 0 numeric 80
## 11 VIP 6213 95.31 158 2.42 0 0 logical 2
## 12 RoomService 4178 64.09 133 2.04 0 0 numeric 1088
## 13 FoodCourt 4096 62.83 137 2.10 0 0 numeric 1247
## 14 ShoppingMall 4187 64.23 161 2.47 0 0 numeric 951
## 15 Spa 3980 61.05 146 2.24 0 0 numeric 1103
## 16 VRDeck 4155 63.74 134 2.06 0 0 numeric 1086
## 17 Name 0 0.00 150 2.30 0 0 factor 6355
## 18 Transported 3236 49.64 0 0.00 0 0 logical 2
## 19 GroupSize 0 0.00 0 0.00 0 0 integer 8
miss = summary(aggr(dados_treino, sortVar=TRUE))$combinations
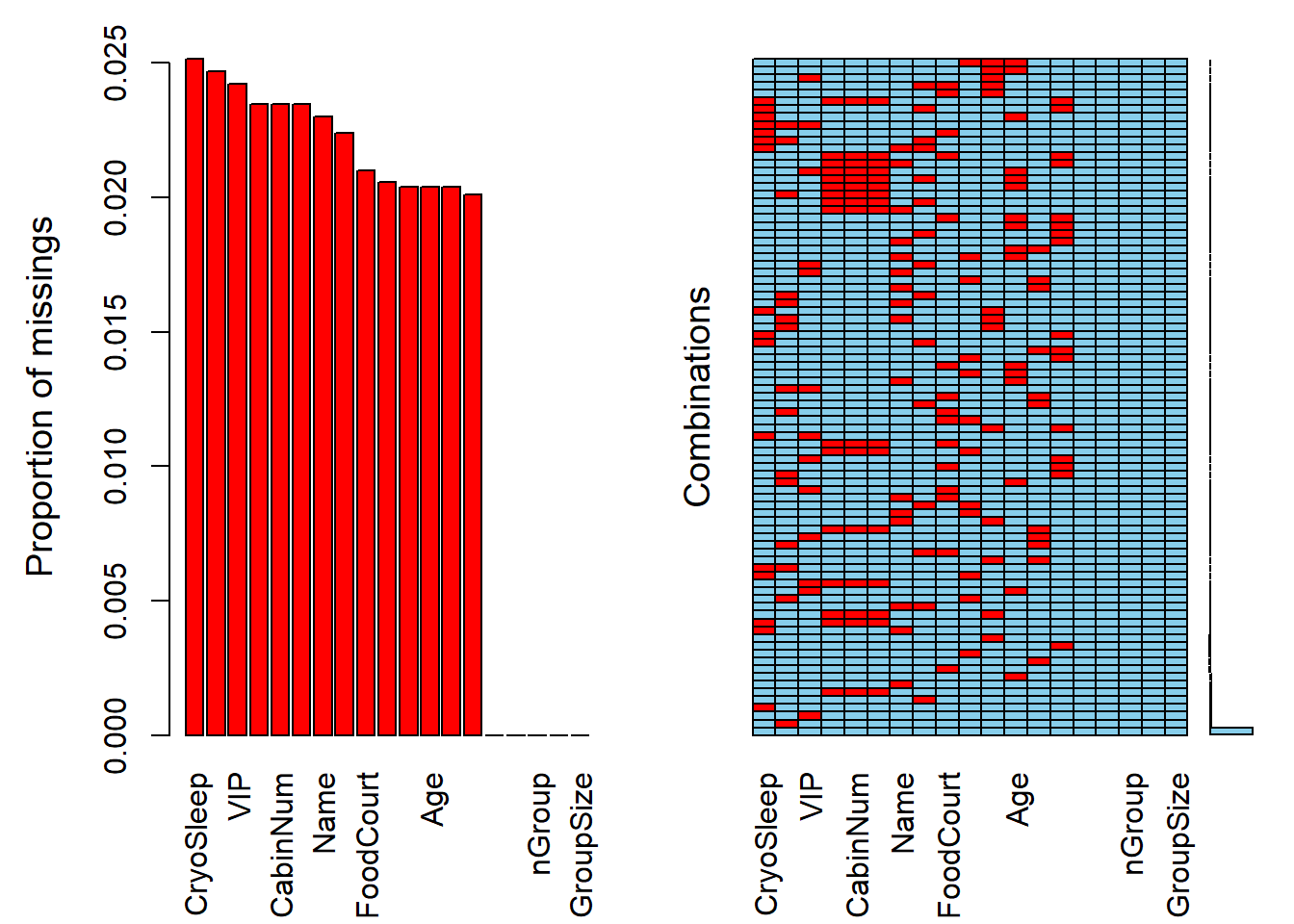
##
## Variables sorted by number of missings:
## Variable Count
## CryoSleep 0.02515723
## ShoppingMall 0.02469704
## VIP 0.02423685
## CabinDeck 0.02346986
## CabinNum 0.02346986
## CabinSide 0.02346986
## Name 0.02300966
## Spa 0.02239607
## FoodCourt 0.02101549
## VRDeck 0.02055530
## HomePlanet 0.02040190
## Age 0.02040190
## RoomService 0.02040190
## Destination 0.02009511
## PassengerId 0.00000000
## PassGroup 0.00000000
## nGroup 0.00000000
## Transported 0.00000000
## GroupSize 0.00000000
O gráfico acima mostra (à esquerda) mostra a proporção de missing values para cada variável da base de dados e todas as combinações de valores ausentes (vermelho) e observados (azul) presentes nos dados (gráfico à direita).
head(miss[rev(order(miss[,2])),])
## Combinations Count Percent
## 1 0:0:0:0:0:0:0:0:0:0:0:0:0:0:0:0:0:0:0 4974 76.300046
## 23 0:0:0:0:0:0:0:0:0:0:1:0:0:0:0:0:0:0:0 128 1.963491
## 8 0:0:0:0:0:0:0:0:0:0:0:0:0:1:0:0:0:0:0 128 1.963491
## 60 0:0:0:0:1:0:0:0:0:0:0:0:0:0:0:0:0:0:0 124 1.902132
## 5 0:0:0:0:0:0:0:0:0:0:0:0:0:0:1:0:0:0:0 121 1.856113
## 47 0:0:0:0:0:1:1:1:0:0:0:0:0:0:0:0:0:0:0 117 1.794754
Note que, apesar de termos aproximadamente 2,5% de dados faltantes em cada variável, temos na base de dados aproximadamente 76% de casos completos, inviabilizando o descarte dessas observações incompletas.
No entanto, é importante avaliar os efeitos do tratamento dos valores ausentes na análise e nos resultados finais, para garantir que as decisões tomadas sejam embasadas e coerentes com os objetivos do estudo. Esse processo deverá ser feito com parcimônia, sob pena de causar um viés de informação. A imputação pode introduzir viés de informação na medida em que os valores imputados podem não ser representativos da realidade ou podem não capturar a variabilidade dos dados ausentes.
Para realizar a imputação das variáveis usaremos as seguintes estratégias:
-
Para as variáveis CryoSleep, RoomService, FoodCourt, ShoppingMall, Spa e VRDeck: Se CryoSleep é missing e pelo menos uma das variáveis de gastos for maior que zero, então imputaremos CryoSleep como FALSE (Se tem gasto, significa que não está em suspensão profunda). Se CryoSleep é TRUE e alguma variável de gastos for missing, então essa variável será imputada com o valor zero (Quem está em suspensão profunda não tem gastos). Além disso, imputaremos o restante dos missings utilizando imputação knn, considerando 2 vizinhos e as variáveis PassGroup, CabinDeck, CabinNum, CabinSide.
-
As demais variáveis serão imputadas utilizando bagged trees.
Podemos então construir nossa receita para realizar todo o pré-processamento:
STRecipe = recipe(Transported ~ ., data = dados_treino) %>%
update_role(PassengerId, Name, new_role = "ID") %>%
step_mutate(
IsAlone = ifelse(GroupSize==1, 1, 0) %>% as.factor(),
CabinNum = as.numeric(CabinNum),
nGroup = as.numeric(nGroup),
VIP = as.factor(VIP),
CryoSleep = ifelse((RoomService > 0 | FoodCourt > 0 | ShoppingMall > 0 | Spa > 0 | VRDeck > 0), replace_na(CryoSleep, FALSE),TRUE),
CryoSleep = as.factor(CryoSleep)) %>%
step_impute_knn(CryoSleep, neighbors = 2, impute_with = imp_vars(PassGroup, CabinDeck, CabinNum, CabinSide)) %>%
step_mutate(
RoomService = ifelse(CryoSleep==TRUE, replace_na(RoomService, 0),RoomService),
FoodCourt = ifelse(CryoSleep==TRUE, replace_na(FoodCourt, 0),FoodCourt),
ShoppingMall = ifelse(CryoSleep==TRUE, replace_na(ShoppingMall, 0), ShoppingMall),
Spa = ifelse(CryoSleep==TRUE, replace_na(Spa, 0), Spa),
VRDeck = ifelse(CryoSleep==TRUE, replace_na(VRDeck, 0), VRDeck)
) %>%
step_impute_knn(RoomService, FoodCourt, ShoppingMall, Spa, VRDeck, neighbors = 2,
impute_with = imp_vars(PassGroup, CabinDeck, CabinNum, CabinSide)) %>%
step_impute_bag(Age, VIP, CryoSleep, Destination, HomePlanet, CabinDeck, CabinNum,
CabinSide) %>%
#step_YeoJohnson(RoomService:VRDeck) %>%
step_mutate_at(RoomService:VRDeck, fn= ~log10(. + 1)) %>%
step_mutate(despesasSuperfluas = RoomService + Spa + VRDeck,
despesasBasicas = FoodCourt + ShoppingMall,
Isearth = ifelse(HomePlanet=='Earth', 1, 0) %>% as.factor(),
Iskid = ifelse(Age < 14, 1, 0) %>% as.factor()) %>%
prep(verbose=TRUE)
## oper 1 step mutate [training]
## oper 2 step impute knn [training]
## oper 3 step mutate [training]
## oper 4 step impute knn [training]
## oper 5 step impute bag [training]
## oper 6 step mutate at [training]
## oper 7 step mutate [training]
## The retained training set is ~ 2.03 Mb in memory.
dados_prep = bake(STRecipe, new_data = NULL)
dados_prep %>%
summary()
## PassengerId PassGroup nGroup HomePlanet CryoSleep
## 0002_01: 1 Min. : 2 Min. :1.000 Earth :3557 FALSE:3912
## 0003_01: 1 1st Qu.:2306 1st Qu.:1.000 Europa:1643 TRUE :2607
## 0004_01: 1 Median :4605 Median :1.000 Mars :1319
## 0005_01: 1 Mean :4620 Mean :1.515
## 0006_01: 1 3rd Qu.:6880 3rd Qu.:2.000
## 0006_02: 1 Max. :9280 Max. :8.000
## (Other):6513
## CabinDeck CabinNum CabinSide Destination Age
## F :2155 Min. : 1 P:3264 55 Cancri e :1361 Min. : 0.00
## G :1952 1st Qu.: 487 S:3255 PSO J318.5-22: 608 1st Qu.:19.00
## E : 649 Median : 922 TRAPPIST-1e :4550 Median :27.00
## B : 603 Mean : 889 Mean :28.72
## C : 603 3rd Qu.:1256 3rd Qu.:37.00
## D : 365 Max. :1722 Max. :79.00
## (Other): 192
## VIP RoomService FoodCourt ShoppingMall
## FALSE:6371 Min. :0.0000 Min. :0.0000 Min. :0.0000
## TRUE : 148 1st Qu.:0.0000 1st Qu.:0.0000 1st Qu.:0.0000
## Median :0.0000 Median :0.0000 Median :0.0000
## Mean :0.7804 Mean :0.8486 Mean :0.7144
## 3rd Qu.:1.7324 3rd Qu.:1.9031 3rd Qu.:1.4771
## Max. :4.1562 Max. :4.4744 Max. :4.3709
##
## Spa VRDeck Name GroupSize
## Min. :0.0000 Min. :0.0000 Alraium Disivering: 2 Min. :1.000
## 1st Qu.:0.0000 1st Qu.:0.0000 Ankalik Nateansive: 2 1st Qu.:1.000
## Median :0.0000 Median :0.0000 Anton Woody : 2 Median :1.000
## Mean :0.8172 Mean :0.7757 Apix Wala : 2 Mean :1.781
## 3rd Qu.:1.7782 3rd Qu.:1.6532 Asch Stradick : 2 3rd Qu.:2.000
## Max. :4.3504 Max. :4.3826 (Other) :6359 Max. :8.000
## NA's : 150
## Transported IsAlone despesasSuperfluas despesasBasicas Isearth Iskid
## Mode :logical 0:2563 Min. : 0.000 Min. :0.0000 0:2962 0:5795
## FALSE:3236 1:3956 1st Qu.: 0.000 1st Qu.:0.0000 1:3557 1: 724
## TRUE :3283 Median : 2.210 Median :0.6021
## Mean : 2.373 Mean :1.5629
## 3rd Qu.: 4.394 3rd Qu.:2.9442
## Max. :10.508 Max. :7.6354
##
Outras transformações se fazem necessárias e serão realizadas em momento oportuno.
Introdução à Mineração de Dados
Semestre 2024-1
Disciplina eletiva oferecida pelo Departamento de Estatística.